%20(2).png)
python
python 的基本规则
-
Python 在表示缩进时可用 tab 键或空格键,但不要将两者混合使用
-
python 用相同的缩进表示同一级别的语句块,不正确的缩进会导致程序逻辑错误
-
对关键代码可以添加必要的注释,以“#”开头表示单行注释,三引号(三个单引号或三个双引号)括起来的内容可用于单行或多行注释
例如:
#这是单行注释
‘’’
这是多行注释
可以注释多行文字
注释的代码并会被程序识别,所以不会被程序执行,必要时还可以把不需要的代码注释掉
‘’’
help() 帮助函数
-
使用 python 提供的 help()函数可以获得相关对象的帮助信息。可以获得 print() 函数的帮助信息,包括该函数大的语法、功能面熟和各参数的含义等。
print(help(print))print(…)
print(value, …, sep=’ ‘, end=’\n’, file=sys.stdout, flush=False) Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
变量名的命名基本规则
-
变量的命名必须遵守的规则:
1. 必须以字母或下划线开头,不能以数字开头,其余部分可以是字母、下划线或者数字。错误示范:3month
2. 不能有空格和标点符号(如括号、引号、逗号、斜线、反斜线、冒号、句号、问号等)。错误示范:sum,1 x$2
3. 不能使用 python 的关键字、标识符、内置函数名等系统保留字。关键字是指已被 python 使用的标识符,用来表达特定语义,不允许通过任何方式改变它们的含义。 错误示范:and
4.python 变量名对字母大小写敏感。例如 Name 和 name 是不同的变量。
5. 变量名称应见名知意。例如,表示学生人数的变量可以定义为 student_number。推荐采用这种以下划线分割的命名方式。
6. 变量名也不能跟内置函数名重名,不然会覆盖内置函数原有的功能。 -
关键字和内置函数名在 python 中可以利用 keyword.kwlist 函数输入有哪些
import keyword print(keyword.kwlist)[‘False’, ‘None’, ‘True’, ‘and’, ‘as’, ‘assert’, ‘async’, ‘await’, ‘break’, ‘class’, ‘continue’, ‘def’, ‘del’, ‘elif’, ‘else’, ‘except’, ‘finally’, ‘for’, ‘from’, ‘global’, ‘if’, ‘import’, ‘in’, ‘is’, ‘lambda’, ‘nonlocal’, ‘not’, ‘or’, ‘pass’, ‘raise’, ‘return’, ‘try’, ‘while’, ‘with’, ‘yield’]
代码缩进
- Python 语言采用严格的“缩进”来表明程序的格式框架。缩进指每一行代码开始前的空白区域,用来表示代码之间的包含和层次关系。
- 1 个缩进 = 4 个空格
- 缩进是 Python 语言中表明程序框架的唯一手段
- 当表达分支、循环、函数、类等程序含义时,在 if、while、for、def、class 等保留字所在完整语句后通过英文冒号(:)结尾,并在之后进行缩进,表明后续代码与紧邻无缩进语句的所属关系。
- 缩进种类有单层缩进和多层缩进

Pycharm 快捷键
ctrl + alt + Y — pycharm 中刷新文件夹
ctrl + shift + Z — 取消撤销退格
ctrl + Z — 撤销
第三方库位置
自己的 python 装的第三方库的位置都在:D:\Python\Lib\site-packages 这里了
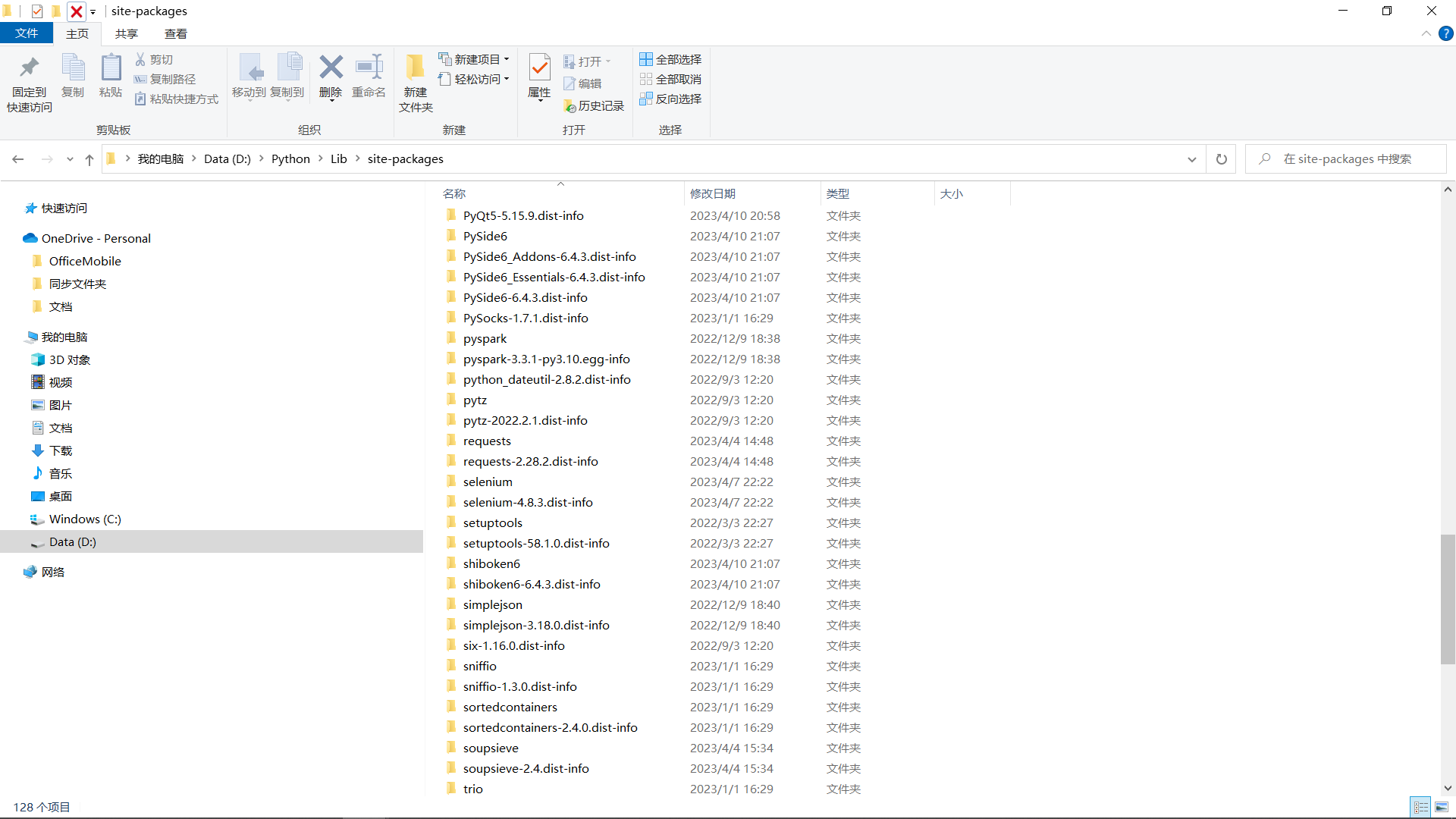
文件路径
python 的文件路径的 \ 号有两种方法表示
- 第一种:\\ 通过两个转义字符 \ 来让反斜杠不出问题
- 第二种:使用这种符号 / 来替代文件路径中的 \ 这个符号,这种符号就不需要使用两个反斜杠了
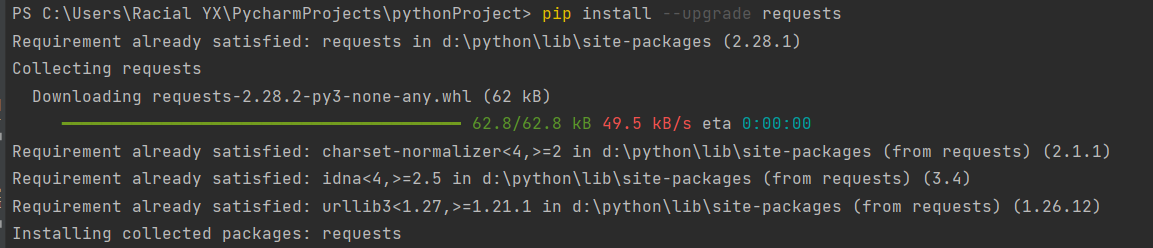
代码指令
更新包名称
pip install --upgrade 包名称
字符串
1. 字符串的顺序
Python 语言中,字符串是用两个双引号“ ”或者单引号‘ ’括起来的一个或多个字符。
Python 字符串的两种序号体系
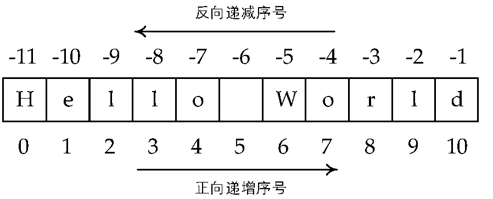
注意正序是从 0 开始的,倒序是从 -1 开始的
如果字符串长度为 L,正向递增需要以最左侧字符序号为 0,向右依次递增,最右侧字符序号为 L-1
反向递减序号以最右侧字符序号为 -1,向左依次递减,最左侧字符序号为 -L。
2. 字符串的索引
字符串索引时可以根据其序号进行索引所需要的字符,表达式为变量名 [索引字符的序号],比如
a='零一二三四'
print(a[2])
二
如果需要用到连续的字符,则可以使用切片。
切片为变量名 [N: M] 格式获取字符串的子串,这个操作被形象地称为切片。
变量名 [N: M]:获取字符串中从 N 到 M(但不包含 M)间连续的子字符串。
a='零一二三四'
print(a[0:3]) #是获取顺序为0-2总共3个字符的切片
零一二
如果变量名 [N:M] 中的 N 没了,则表示的是获取从 0~M 的字符切片,形式为[:M]
a='零一二三四五六七八九十'
print(a[:5]) #表示获取的是从顺序为0~4的字符串
零一二三四
反过来,如果 ** 变量名 [N:M]** 中的 M 没了,则表示的是获取从 N~(-1) 的字符串, 形式为[N:]
a='零一二三四五六七八九十'
print(a[3:]) #表示获取的是从顺序为3到结尾的字符串
三四五六七八九十
字符串切片的高级用法
使用 [M: N: K],根据步长 K 对字符串进行切片:意思是从顺序 M 开始每隔 K 个字符取一个字直到 N 结束
a='零一二三四五六七八九十'
print(a[1:9:2]) #从顺序1开始取第一个数字后,每隔2个字符,取一个字符直到第8个字符结束,注意第9个字符是不包含在里面的
一三五七
3. 字符串的操作与处理方法
"方法" 在编程中是一个专有名词, 字符串及变量也是存在一些方法
方法特指变量名 / 字符串. 函数名 () 风格中的函数名 ()
函数与变量名 / 字符串有关,一般为变量名 / 字符串. 函数名 ()
大小写转换
-
str.lower()或 str.upper():返回字符串的副本,全部字符小写或大写, 当然也能用
变量名.upper() 或变量名.lower()
#全部小写 print('ABCDEFG'.lower()) #全部大写 print('abcdefg'.upper())abcdefg
ABCDEFG -
str.capitalize():将字符串的第一个字母变成大写, 其他字母变小写。对于 8 位字节编码需要根据本地环境
str1='this is an EXAMPLE to sHoW' print('新str1为:',str1.capitalize()) str2='this is a apple,AND that is a banana' print('新str2为:',str2.capitalize())新 str1 为: This is an example to show
新 str2 为: This is a apple,and that is a banana -
str.title():把字符串的每个单词首字母大写
str1='the initial word will be become uppercase letter' print(str1.title())The Initial Word Will Be Become Uppercase Letter
-
string.swapcase():用于对字符串的大小写字母进行转换,即将大写字母转换为小写字母,小写字母会转换为大写字母
str1='tHIS iS a lETTER' print(str1.swapcase())This Is A Letter
文本对齐
-
str.center(width, 填充的字符):返回一个原字符串居中,并用填充字符 (默认空格) 填充至指定长度为 width 的新字符串 (str 里面的字符也一起算进 width 里面)
a='我是填充字符,我被填充至中间' print(a.center(40,'—'))—————————————我是填充字符,我被填充至中间—————————————
-
str.ljust(width, 填充的字符):返回一个原字符串进行左对齐, 并使用填充字符 (默认空格) 填充至指定长度为 width 的新字符串。如果指定的长度小于原字符串的长度则返回原字符串。
str1='我将会被ljust()函数放在最左边' print(str1.ljust(40,'-')) str2='如果设置的指定长度不够长,将返回原字符串' print(str2.ljust(5,'-'))我将会被 ljust() 函数放在最左边 ----------------------
如果设置的指定长度不够长,将返回原字符串 -
str.rjust(width, 填充的字符):返回一个原字符串进行右对齐, 并使用填充字符 (默认空格) 填充至长度 width 的新字符串。如果指定的长度小于字符串的长度则返回原字符串。用法跟上述相同,这里不写代码举例了。
拆分和连接
-
str.join(元组变量名):在可迭代对象的元组里面除最后一个元素外,在每个元素后增加所需要的一个 str
a='-' b='' iter=('r','u','n','n','e','r') #这是可迭代对象:元组 print('第一个输出为:',a.join(iter)) print('第二个输出为:',b.join(iter))第一个输出为: r-u-n-n-e-r
第二个输出为: runner -
str.partition(指定的字符为分隔符) :用来根据指定的分隔符将字符串进行分割,这里是从左边开始进行查找后才拆分。如果字符串包含指定的分隔符,则返回一个 3 元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串
返回值:返回一个 3 元的元组
str1='在字符串中用字符串中所包含有的指定字符将这一整段字符串分隔成3段' str2=str1.partition('指定字符') print(str2,'\t''然后可以返回第一段字符串:',str2[0]) str3='www.baidu.com' print(str3.partition('.'))(‘在字符串中用字符串中所包含有的’, ‘指定字符’, ‘将这一整段字符串分隔成 3 段’) 然后可以返回第一段字符串: 在字符串中用字符串中所包含有的
(‘www’, ‘.’, ‘baidu.com’) -
str.rpartition(指定的字符为分隔符) :方法类似于 str.partition(),只是该方法是从目标字符串的末尾也就是右边开始搜索分割符。
如果字符串包含指定的分隔符,则返回一个 3 元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串
返回值:返回一个 3 元的元组
str1='在一段字符串中(我是指定分隔符但没有进行拆分)从最右边先查找字符串所包含有的指定分隔符然后再进行拆分' print(str1.rpartition('指定分隔符')) #注意partition是左边的点开始拆分,rpartition是从右边的点开始拆分 str2='www.baidu.com' print('这是从左边开始:',str2.partition('.'),'\n''这是从右边开始:',str2.rpartition('.'))(‘在一段字符串中(我是指定分隔符但没有进行拆分)从最右边先查找字符串所包含有的’, ‘指定分隔符’, ‘然后再进行拆分’)
这是从左边开始: (‘www’, ‘.’, ‘baidu.com’)
这是从右边开始: (‘www.baidu’, ‘.’, ‘com’) -
str.split(指定的字符变成分隔符, 分隔次数): 通过指定的字符串变成分隔符(默认为所有的空字符,包括空格、换行 (\n)、制表符 (\t))对字符串进行切片,如果第二个参数有指定值(默认为 -1 次),则分割为 指定次数 +1 个子字符串。
返回值:返回分割后的字符串列表
str1='这是(指定字符串变成分隔符)一个(指定字符串变成分隔符)例子' print(str1.split('(指定字符串变成分隔符)',1)) print(str1.split('(指定字符串变成分隔符)',2))[‘这是’, ‘一个(指定字符串变成分隔符)例子’]
[‘这是’, ‘一个’, ‘例子’] -
str.splitlines(False/True):如果字符串里有(’\n’或’\r’或’\n\r’),则去掉 (’\r’或 '\r\n’或 ‘\n’) 从而对字符串进行分隔
返回值:如果参数为 False(默认为 False),则返回不包含换行符的元素列表
如果参数为 True,则返回保留换行符的元素列表
str1='返回\n包含\n\r各行\r元素\r的列表' print(str1.splitlines(False)) print(str1.splitlines(True))[‘返回’, ‘包含’, ‘’, ‘各行’, ‘元素’, ‘的列表’]
[‘返回 \n’, ‘包含 \n’, ‘\r’, ‘各行 \r’, ‘元素 \r’, ‘的列表’]
去除空白符
-
str.strip(要移除的字符串) :用于移除字符串头尾指定的字符(默认为空格)或字符。注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
str1='---移除左右两边的指定字符串-' print(str1.strip('-')) str2='最左右两边的字符串可以移除' print(str2.strip('最左右可以移除'))移除左右两边的指定字符串
两边的字符串 -
str.lstrip(要移除的字符串) :用于移除字符串左边的指定字符(默认为空格)。
str1='----只能移除左边指定的字符---' print(str1.lstrip('-')) print(str1.lstrip('-只能'))只能移除左边指定的字符—
移除左边指定的字符— -
str.rstrip(要移除的字符串):用于移除字符串右边的指定字符(默认为空格)。使用方法跟上述一致,这里不再写代码举例。
解码和编码
-
str.encode(encoding,errors):用来给字符串使用指定的编码格式来编码字符串,str.encode() 方法将会返回经过指定编码格式编码后的字符串,它是一个 bytes 对象。
str – 需要操作的字符串,也就是需要编码的字符串。
encoding – 需要使用的编码,如: UTF-8、GBK 等。
errors – 设置不同错误的处理方案。默认为 ‘strict’, 意为编码错误引起一个 UnicodeError。 其他可能得值有’backslashreplace’, ‘replace’、‘ignore’, ‘xmlcharrefreplace’, 以及通过 codecs.register_error() 注册的任何值
str1='我是大帅逼' print(str1.encode('UTF-8','strict'))b’\xe6\x88\x91\xe6\x98\xaf\xe5\xa4\xa7\xe5\xb8\x85\xe9\x80\xbc’
-
str.decode(decoding):它与 str.encode()相反,是对 bytes 对象进行解码,str.decode() 方法将返回经过指定解码格式解码后的 bytes,它是一个字符串对象。与上述用法相同。
str2=b'\xe6\x88\x91\xe6\x98\xaf\xe5\xa4\xa7\xe5\xb8\x85\xe9\x80\xbc' print(str2.decode('UTF-8'))我是大帅逼
查找和替换
-
str.find(str_sub,start,end):检测母字符串 str 中是否包含子字符串 str_sub,然后在指定 start 和 end 范围内,检查其是否包含子字符串 str_sub,如果母字符串 str 包含子字符串 str_sub 则返回子字符串 str_sub 开始的索引,否则返回 -1。sub 指 subordinate,表示从属的,下级的
str_sub – 需要在母字符串中找到的目标
start – 需要在字符串中寻找目标的起始位置,一般为 0
end-- 需要在字符串中寻找目标的结束位置,一般可以用 len(str) 表示其末尾位置
str1='for example as follow' print('能够找到目标的索引位置:',str1.find('exam',0,len(str1))) #从0开始查找,若查到了。则返回其位置信息 print('无法找到目标,则返回:',str1.find('exam',10,len(str1))) #从长度为10的位置开始查找,起始位置早已超过exam其所在的位置,故肯定找不到 print('则目标的起始位置的字母为:',str1[4])能够找到目标的索引位置: 4
无法找到目标,则返回: -1
则目标的起始位置的字母为: e -
str.index(str_sub, 起始位置, 结束位置):和 str.find() 使用方法相同, 不同点在于它找不到目标时会抛出异常(即报错)
str1='和str.find()使用方法相同' print(str1.index('使用方法',0,len(str1))) #print(str1.index('使用方法',12,len(str1))) 这里先注释掉了,需要验证直接复制粘贴再去掉注释符号 print('找到目标的起始位置字符是:',str1[11])11
#找不到报错
Traceback (most recent call last):
File “C:\Users\Racial YX\PycharmProjects\pythonProject\4.py”, line 5, in
print(str1.index(‘使用方法’,12,len(str1)))
ValueError: substring not found找到目标的起始位置字符是: 使
-
str.replace(旧字符, 新字符, 替换次数最大值):把字符串中的 old 字符替换为 new 字符,如果指定第三个参数,则替换次数不超过指定的最大值。
这个只能进行单一的替换,即只能换一种字符,若要换多个字符,则必须用连续相邻且紧挨着的作为字符作为一 个整体进行替换
a='they are student' print('a为:',a.replace('aeiou',' '))#替换无效,因为没有aeiou这个组成的整体,输出依然为they are student b='i am a apple' print('b为:',b.replace('a','*',4))a 为: they are student
b 为: i *m * *pple -
str.count(‘字符串’/ 字母 / 数字):返回子串 sub 在 str 中出现的次数, 一样也可以用变量名.count(sub)
a='a apple a day' print(a.count('a')) print('—'.center(19,'—')) print('123,321,1234567'.count('1'))4
———————————————————
3
运算符
1. 关系运算符
关系运算符用来比较两个值的大小,运算的结果为逻辑型的值 True 或 False
| 运算符 | 功能 | 示例 |
|---|---|---|
| == | 等于 | a == b |
| != | 不等于 | a != b |
| > | 大于 | a > b |
| >= | 大于等于 | a >= b |
| < | 小于 | a < b |
| <= | 小于等于 | a <= b |
2. 算术运算符
| 运算符 | 功能 | 示例 |
|---|---|---|
| - | 求负数运算 | -a |
| + | 加运算 | a + b |
| - | 减运算 | a - b |
| ***** | 乘运算 | a * b |
| / | 除运算 | a / b |
| // | 整除运算 | a // b |
| % | 求余(取模)运算 | a % b |
| ** | 幂(指数)运算 | a ** b |
3. 赋值运算符
| 运算符 | 功能 | 示例 |
|---|---|---|
| += | 加法赋值运算符 | b+= a 等效于 b = b + a |
| -= | 减法赋值运算符 | b-= a 等效于 b = b - a |
| *= | 乘法赋值运算符 | b= a 等效于 b = b * a* |
| /= | 除法赋值运算符 | b/= a 等效于 b = b / a |
| //= | 整除赋值运算符 | b//= a 等效于 b = b // a |
| %= | 求余赋值运算符 | b%= a 等效于 b = b % a |
| **= | 幂赋值运算符 | b****= a 等效于 b = b ****a |
幂赋值运算符其实还可以用 **pow(x, 幂次方)** 形式函数
print('方法一')
a1=5**3
print('5的3次方为:',a1)
print('方法二')
print('5的3次方为:',pow(5,3))
方法一
5 的 3 次方为: 125
方法二
5 的 3 次方为: 125
4. 位运算符
位运算符是将操作数视为二进制数并按位进行运算,多用于外设控制或需要按位处理的情况 (例如图像处理)。
| 运算符 | 功能 | 示例 |
|---|---|---|
| ~ | 按位取反运算符 | ~ a |
| & | 按位与运算符 | a & b |
| | | 按位或运算符 | a | b |
| ^ | 按位异或运算符 | a ^ b |
| >> | 右移位运算符 | a >> b |
| << | 左移位运算符 | a << b |
python 中常用类型转换函数
| 函数格式 | 描述 |
|---|---|
| int(x,[base]) | 将字符串和其他数值类型的数据转换成整型 |
| float(x) | 将字符串和其他数值类型转换成浮点数 |
| complex(real,imag) | real 可以是字符串或者数字;image 只能为数字类型,默认为 0 |
| str(x) | 将数值转化为字符串 |
| repr(x) | 返回一个对象的字符串格式 |
| eval(str) | 将 str 转换成表达式,并返回表达式的运算结果 |
| tuple(seq) | 将 seq 转为元组,seq 可为列表、集合或字典 |
| list(s) | 将序列转变成一个列表,s 可为元组、字典、列表 |
| set(s) | 将一个可迭代对象转变为集合 |
| chr(x) | 返回整数 x 对应的 unicode 字符 |
| ord(x) | 返回字符 x 对应的 ASCII 码或 Unicode 码 |
| hex(x) | 把整数 x 转换为十六进制字符串 |
| oct(x) | 把整数 x 转换为八进制字符串 |
转义字符
转义字符:是一些有特殊含义且难以用一般方式表达的字符,例如回车符、换行符等,“\ 特殊字符”表达转义。
| 转义字符 | 描述 |
|---|---|
| \ 行尾 | 续行符 |
| \\ | 反斜杠符号 |
| \’ | 单引号 |
| \’’ | 双引号 |
| \a | 响铃 |
| \b | 退格 (Backspace) |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符(tablet),产生四个孔空字符,与键盘上的 Tab 键效果一致 |
| \r | 回车 |
| \f | 换页 |
| \0yy | 八进制数,yy 代表八进制数,例如 \012 表示十进制的 10 |
| \xyy | 十六进制数,yy 代表十六进制数,例如 \x1a 表示十进制的 26 |
| \other | 其它字符以普通格式输出 |
转义字符的使用
1. 续行符的使用
print('这是一段文本\
这是另外一段文本')
a=5+\
2
print(a) #a是7
这是一段文本这是另外一段文本
7
2. 反斜杠的使用
在 python 中要使用一个反斜杠符号就需要使用两个杠 \\ 才能表示为一个反斜杠,不然只用一个反斜杠会被认为是转义字符
print('反斜杠符号的使用\\这里有一个反斜杠')
反斜杠符号的使用 \ 这里有一个反斜杠
3. 单引号的使用
双引号同理
print('I\'m a student') #在这里要用\'在才能输出单引号,直接使用单引号
print('I'm a student') #去掉反斜杠会报错
I’m a student
第二段代码会报错
4. 换行的使用
换行的方法有好几种
方法一:end=’\n’或者直接’\n’ ;只要保证 **\n** 在字符串内就可以了
print('进行换行演示',end='\n''这里进行了换行') #不要忘了end前面要加个逗号,不然会报错
print('进行换行演示'end='\n''这里进行了换行') #这个end前面无逗号会报错哦
print('这样表示','\n''也是一样的')
print('只要符号在字符串里\n一样可以换行')
进行换行演示
这里进行了换行
这样表示
也是一样的
只要符号在字符串里
一样可以换行
方法二:直接 print(), 表示直接空出一行
print('第一行')
print()
print('第二行')
第一行
第二行
5. 退格的使用
\b------ 相当于删除了前面的一个字符
print('退格 删\b相当于删除了前面的一个字符')
退格 相当于删除了前面的一个字符
6. 横向制表符的使用
print('\t1234')
print('12345678')
print('1\t234') #前面占有1个位符,后面空出3个位符
print('12345678')
print('12\t34') #前面占有2个位符,后面空出2个位符
print('12345678')
print('123\t4') #前面占有3个位符,后面空出1个位符
print('12345678')
print('1234\t5678') #前面占有4个位符,\t会重新开一行,后面空出4个位符
print('12345678')
1234 12345678 1 234 12345678 12 34 12345678 123 4 12345678 1234 5678 12345678
横向制表符 \t 需要看其前面占有多少位符,决定后面会空出多少个位符,对阿拉伯数字和英文字母有用,但是对汉字含义不一样,因为一个汉字是占 2 个位符的
进制之间的转换
原理:python 内置函数进行进制转换的原理是将读入的一个字符串 (python 默认读入的都是字符串形式) 转为 10 进制,然后再用相关函数进行其他进制转换
| x 为 2 进制数 | x 为 8 进制数 | x 为 10 进制数 | x 为 16 进制数 | ||||
|---|---|---|---|---|---|---|---|
| 2 转 8 进制 | oct(int(‘x’,2)) | 8 转 2 进制 | bin(int(‘x’,8)) | 10 转 2 进制 | bin(int(‘x’,10)) | 16 转 2 进制 | bin(int(‘x’,16)) |
| 2 转 10 进制 | int(‘x’,2) | 8 转 10 进制 | int(‘x’,8) | 10 转 8 进制 | oct(int(‘x’,10)) | 16 转 8 进制 | oct(int(‘x’,16)) |
| 2 转 16 进制 | hex(int(‘x’,2)) | 8 转 16 进制 | hex(int(‘x’,8)) | 10 转 16 进制 | hex(int(‘x’,10)) | 16 转 10 进制 | int(‘x’,16) |
这里由于表格已经塞不下了,只能简单的表示,实际上,表格最上行写的 x 为 2 进制数写全为:x 为输入的 2 进制数,其他同理
由于我们平时用的就是 10 进制,所以 10 进制可以直接转换成其他进制,不用再带个 int,可以简写成对应的 bin()、oct()、hex()
这里举 2 进制转换成 8、10、16 进制的例子
print(oct(int('10101',2))) #2进制转换成8进制
print(int('10101',2)) #2进制转换成10进制
print(hex(int('10101',2))) #2进制转换成16进制
0o25
21
0x15
其他的也一样,要注意的点在于’x’表示’输入对应进制数’,这里的双引号一定要记得加
print(oct(int(10101,2)))#这里的x位置是没有加引号的,会报错,一定要加引号
Traceback (most recent call last):
File “C:\Users\Racial YX\PycharmProjects\pythonProject\d.py”, line 3, in
print(hex(int(10101,2))) #2 进制转换成 16 进制
TypeError: int() can’t convert non-string with explicit base
数值运算函数
| 函数及使用 | 描述 | 举例 |
|---|---|---|
| abs(x) | 绝对值,x 的绝对值 | abs(-10.01) 结果为 10.01 |
| divmod(x,y) | 商余,(x//y, x%y),同时输出商和余数 | divmod(10, 3) 结果为 (3, 1) |
| pow(x, y[, z]) | 幂余,(x**y)%z,[…] 表示参数 z 可省略 | pow(3, pow(3, 99), 10000) 结果为 4587 |
| round(x[, d]) | 四舍五入,d 是保留小数位数,默认值为 0 | round(-10.123, 2) 结果为 -10.12 |
| max(x1,x2, … ,xn) | 最大值,返回 x1,x2, … ,xn 中的最大值,n 不限 | max(1, 9, 5, 4, 3) 结果为 9 |
| min(x1,x2, … ,xn) | 最小值,返回 x1,x2, … ,xn 中的最小值,n 不限 | min(1, 9, 5, 4, 3) 结果为 1 |
| int(x) | 将 x 变成整数,舍弃小数部分 | int(123.45) 结果为 123; int(“123”) 结果为 123 |
| float(x) | 将 x 变成浮点数,增加小数部分 | float(12) 结果为 12.0; float(“1.23”) 结果为 1.23 |
| complex(x) | 将 x 变成复数,增加虚数部分 | complex(4) 结果为 4 + 0j |
format() 方法控制字符串
表达式为:*’’{参数序号: 格式化控制标记}’’.format(填充的内容, 多个参数序号用逗号隔开)
当然现在也能简写为:f"{特定序列} 这种格式"
例如
a="这种形式{1}也可以调换顺序,{0}也可以拥有多个参数,{2}要注意format格式后面的顺序是固定的正序".format('同时','当然','不过')
print(a)
b='使用填充字符*,对齐方式为居中对齐^,宽度为30个字母,保留浮点型小数的2为小数(注意前面有个逗号),类型为f(浮点数)为:\n{0:-^30.2f}\n当然这里也可以体现一下同时使用多个进行精准控制哦,这里是举例的另外一个控制\n{1:=>20.4f}'.format(3.14159265,1.23456789)
print(b)
这种形式当然也可以调换顺序,同时也可以拥有多个参数,不过要注意 format 格式后面的顺序是固定的正序
使用填充字符 *,对齐方式为居中对齐 ^,宽度为 30 个字母,保留浮点型小数的 2 为小数(注意前面有个逗号),类型为 f(浮点数)为:
-------------3.14-------------
当然这里也可以体现一下同时使用多个进行精准控制哦,这里是举例的另外一个控制
==============1.2346
None 类型的应用场景
-
None 作为一种特殊的字面量,用于表示:空,无意义
-
None 可以用于无返回值上
-
None 用于 if 的判断上
- 在 if 判断中,None 等同于 False
- 一般用于在函数中主动返回 None,配合 if 判断做相关处理
-
None 用于声明无内容的变量上
- 定义变量,但暂时不需要变量有具体值,可以用 None 来代替,可以防止报错
name=None #暂不赋予具体变量值 print(name) #这样可以防止报错None
-
控制循环语句
continue 语句
作用:中断本次内部循环,直接进入下一次内部循环,在 for 和 while 循环中,效果一致
for i in range(1,11):
if i%2==0:
continue #这里表示当i整除到2的时候,开始执行continue的功能,即为中断执行,重新跳回i=3开始继续循环,每当i能够整除2时即中断循环
print(i)
print('==分割线==')
for i in range(1,11):
if i%2==0:
print(i)
#会发现这里有continue求出来的是奇数,无continue求出来的是偶数
1
3
5
7
9
分割线
2
4
6
8
10
break 语句
作用:是直接中断了内部循环,直接进入下一次的外部循环(有嵌套结构的话),在 for 和 while 循环中,效果一致
for i in range(1,11):
if i%2==0:
break
print(i)
#直接中断了内部循环停止了
for i in range(1,4):
for j in range(4,8):
if j==6:
print('每当j=6时,break会结束内部j的循环,然后进入外部i的循环')
break
print(f'{i}+{j}={i+j}')
1
1+4=5 1+5=6 每当j=6时,break会结束内部j的循环,然后进入外部i的循环 2+4=6 2+5=7 每当j=6时,break会结束内部j的循环,然后进入外部i的循环 3+4=7 3+5=8 每当j=6时,break会结束内部j的循环,然后进入外部i的循环

def 函数
-
def 函数名 (传入参数):
函数体
return 返回值
-
返回值:函数在执行完成后,返回给调用者的结果
- 函数体在遇到 return 后就结束了,所以写在 return 后的代码不会执行

- 若函数没有使用 return 语句返回数据,那么函数会自动返回一个 None 的字面量,表示返回了无意义的内容
-
函数的调用:函数名 (参数)
- 参数如不需要,可以省略
- 返回值如不需要,可以省略
- 函数必须先定义后使用
- 可以含有多个传入参数,但是需要用逗号隔开
- 进行函数的调用时,参数数量与格式必须与传入参数一致
定义一个具有加法功能和与 len 一样能计算长度的函数
def add(x,y): result=x+y return result print(f'使用时可以输入任意两个参数从而实现加法功能:{add(5,4)}') a,b=eval(input('请输入任意两个参数,中间用英文逗号隔开:')) #输入5,6 print(f'任意两个参数相加的结果为:{add(a,b)}') ---------------------------------------------------------------------------- #定义一个具有计算长度的功能 def lenth(data): count=0 for i in data: count=count+1 return count a='这个长度为6' print(f'此字符串的长度为:{lenth(a)}')使用时可以输入任意两个参数从而实现加法功能:9
请输入任意两个参数, 中间用英文逗号隔开:5,6
任意两个参数相加的结果为:11
此字符串的长度为:6
函数的说明文档
语法如下:

例如
#定义一个函数1
def fun_a():
'''
函数说明,文档注释
:param x:请玩家输入整数
:param a:生成一个0-20的随机整数
:range(2):可以玩2次
:return:返回空值
'''
import random
print('竞猜游戏开始了!')
for i in range(2):
x=eval(input('请您猜一个整数(1~20):'))
a=random.randint(1,21)
if x==a:
print('您猜中了!')
break
if x<a:
print('您猜的数太小了')
else:
print('您猜的数太大了')
return None
print(fun_a())
竞猜游戏开始了!
请您猜一个整数(1~20):15
您猜的数太小了
请您猜一个整数(1~20):14
您猜的数太大了
None
函数的嵌套调用
- 定义:一个函数里面又调用了另外一个函数
- 执行流程:函数 A 中执行到调用函数 B 的语句,会将函数 B 全部执行,执行完函数 B 后,继续执行函数 A 的剩余内容
def fun_1():
print('我是函数1')
def fun_2():
print('我是函数2')
def fun_3():
fun_1()
fun_2()
print('我是函数3')
#在函数3里面嵌套使用函数1和2的功能
print(fun_3())
我是函数 1
我是函数 2
我是函数 3
None
变量作用域
-
指变量的作用范围(变量在哪里可用,在哪里不可用)
主要分为两类:全局变量和局部变量
全局变量
-
定义:在函数体内、外都能生效的变量,但是全局变量在函数体内使用时,所有函数体使用的都是同一个全局变量的值,且函数内部只能使用而不能修该全局变量的值
#定义一个全局变量 num=100 def#定义一个全局变量 a=500 def fun_1(): b=a+500 return b def fun_2(): a=a+500 #函数内部不能修改全局变量的值,否则会报错 return a print(f'函数1的值为:{fun_1()}') --------------------------------------- print(fun_2())函数 1 的值为:1000
报错
-
global 关键字:此关键字能在函数内部中声明变量为全局变量,声明后就能够在函数内部就能修改全局变量的值了,且修改后所有函数体的全局变量的值都会进行继承
#定义一个全局变量 num=100 #定义修改函数1 def modify_1(): global num #声明num为全局变量 num=num+400 return num #返回修改后的num值 print(f'num的值修改后为:{modify_1()}') #定义修改函数2 def modify_2(): global num num_2=num+200 #使用了函数1修改过的全局变量的值 return num_2 print(f'函数2的值为:{modify_2()}') #说明全局变量的值具有继承性num 的值修改后为:500
函数 2 的值为:700
局部变量
- 定义:在函数内部的变量,即只在函数内部生效,且函数外部无法使用函数内部的变量,在函数外部访问函数内部的变量则会报错,它是用于临时保存的数据,即当函数调用完成后,则销毁局部变量
#定义一个函数1
def fun_1():
num=10 #定义一个局部变量
for i in range(1,num):
if i%2==0:
print(i)
return i
print(f'当尽心遍历时,return会返回最后一个数值i:{fun_1()}')
2
4
6
8
当尽心遍历时,return 会返回最后一个数值 i:9
函数的多返回值
def 函数名 (形参列表):
函数体
return 返回值 1, 返回值 2, …
--------- 接收结果 -----------
x, y, … = 函数名 ()
函数的传入参数
位置传参
def 函数名 (形参 1, 形参 2, …):
函数体
----------- 调用时 ------------
函数名 (实际参数 1, 实际参数 2, …)
- 调用函数时,根据函数定义的参数位置来传递参数,传入的实际参数的位置必须与形参的位置一样
def user_info(name, age, gender):
print(f"你的名字为{name},年龄为{age},性别是{gender}")
user_info("Tom",20,"男")
你的名字为 Tom,年龄为 20,性别是男
关键字传参
def 函数名 (形参名 1, 形参名 2, …):
函数体
-------- 调用时 --------
函数名 (形参名 1 = 值 1 , 形参名 2 = 值 2 , …)
- 函数调用时通过形参名 = 值的形式传递参数,好处是可以不用按照位置传入参数,在调用时,如果混用位置传参和关键字传参,则位置传参一定要在关键字传参的前面,否则会报错
def user_info(name, age, gender):
print(f"你的名字为{name},年龄为{age},性别是{gender}")
user_info(age = 20,gender = "男",name = "Tom")
你的名字为 Tom,年龄为 20,性别是男
默认值传参
def 函数名 (参数名 1, 参数名 2, 参数名 3 = 默认值, …):
函数体
------- 调用时 -------
函数名 (实参 1, 实参 2, 实参 3 为非默认值 , …)
- 在定义函数时,为参数提供默认值,调用函数时如果该位置不传入新的实参值,则函数体将一直使用默认参数值,如果调用函数时在该位置传入了新的参数值,则函数体会修改默认参数值为新的参数值
- 默认参数值必须定义在形参列表的最后,否则报错
def user_info(name, age, gender="男"):
print(f"你的名字为{name},年龄为{age},性别是{gender}")
# 不传入新的参数值
user_info("Tom", 20)
# 传入新的参数值
user_info("Tom", 20, "女")
你的名字为 Tom,年龄为 20,性别是男
你的名字为 Tom,年龄为 20,性别是女
不定长传参
定义:不定长参数也叫可变参数,用于不确定调用的时候会传递多少个实参 (不传入参数也行) 的场景
位置不定长参数 *
def 函数名 (* 参数名):
函数体
------ 调用时 -------
函数名 (实参 1, 实参 2, …)
- 位置不定长参数使用一个 ==* 参数名就可以无限的将实际参数传进去,传入的参数将被放入一个叫参数名的元组容器 == 中
- 参数名 = (实参 1, 实参 2, …) <— 元组
def user_info(*data):
print(data)
for element in data:
print(element)
user_info("Tom", "歌手", 18)
(‘Tom’, ‘歌手’, 18)
Tom
歌手
18
关键字不定长传参 **
def 参数名 (** 参数名):
函数体
------------ 调用时 ---------
函数名 (key1 = value1, key2 = value2, …)
- 关键字不定长传参是字典类型的传入参数,传入参数时按 key = value 的形式传入参数,并被字典名为 参数名的字典进行接收,从而得到一个存着传入键值对的字典,key 为字符串时不用英文的引号包围,value 为字符串时需要引号包围
def user_info(**user):
print(user)
user_info(name = "Tom",age = 18,salary = 4000)
{‘name’: ‘Tom’, ‘age’: 18, ‘salary’: 4000}
函数作为参数传递
函数本身可以作为一个参数进行传递,传递给另外一个函数
函数名 1(函数名 2) ---- 注意这里函数名 2 作为参数传递时是没有括号的
def add(x, y):
return x + y
def fun(add):
result = add(4,5)
return result
print(f"fun()函数传入add函数:{fun(add)}")
fun() 函数传入 add 函数:9
匿名函数
lambda 匿名函数
lambda 形参列表 : 函数体 (一行代码)
- lambda 是关键字,表示定义匿名函数,且只能临时使用一次
- 函数体只能写一行代码,无法写多行代码
def fun(compute):
result = compute(4, 5)
return result
res1 = fun(lambda x, y: x + y)
res2 = fun(lambda x, y: x * y)
print(f"使用lambda函数作为实参传入参数:{res1}")
print(f"使用lambda函数作为实参传入参数:{res2}")
使用 lambda 函数作为实参传入参数:9
使用 lambda 函数作为实参传入参数:20
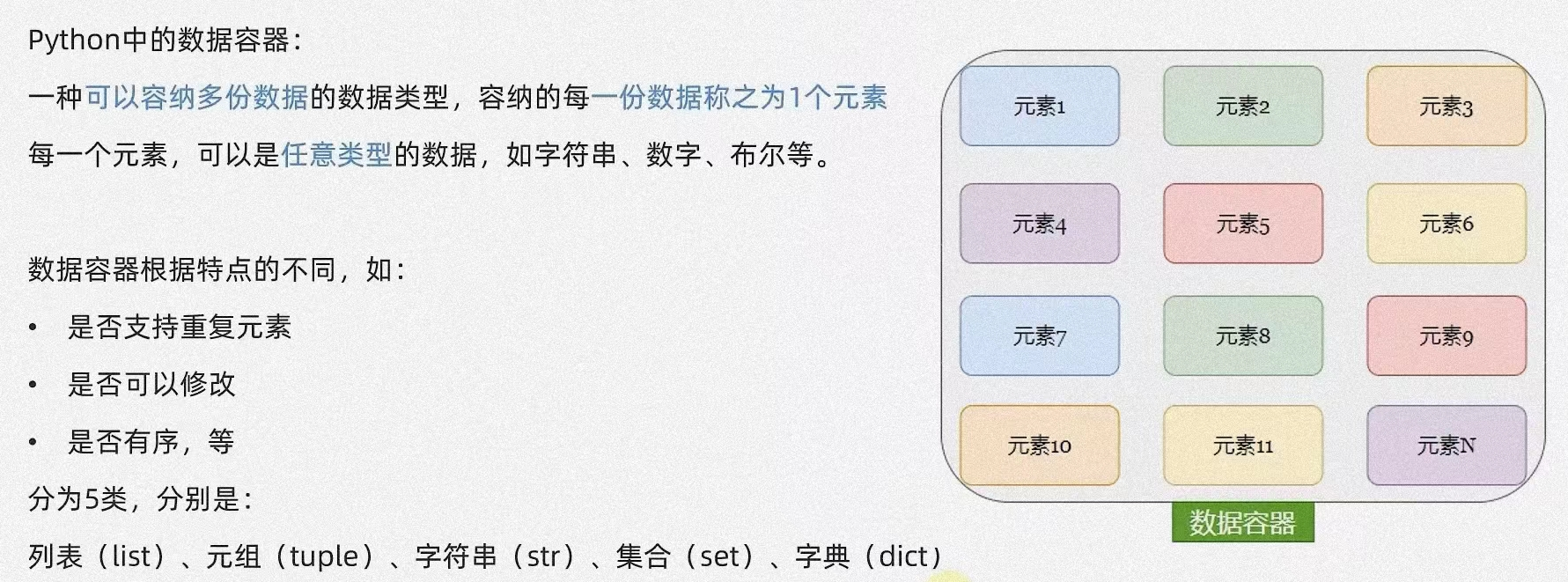
数据容器
-
数据容器的作用:用来存储多个元素的数据类型
-
数据容器的类型:
- 列表 ---- list[]
- 元组 ---- turtle()
- 集合 ---- set()
- 字典 ---- dict{}
列表 (list)
-
列表可以一次存储多个数据,且可以为不同的数据类型,支持嵌套
- 列表的特点:
- 可以容纳多个元素(上限为 2**63-1 个)
- 数据是有序存储的
- 允许重复数据存在
- 可以修改
#列表的创建和支持的数据类型,列表里不用元素之间用逗号隔开 suppot_list=['字符串',666,True] #列表支持嵌套,列表与列表之间用逗号隔开 my_list=[[1,2,3],[4,5,6]] print(f'列表支持的格式有:{suppot_list},嵌套的列表长这样:{my_list}')列表支持的格式有:[‘字符串’, 666, True], 嵌套的列表长这样:[[1, 2, 3], [4, 5, 6]]
- 列表的特点:
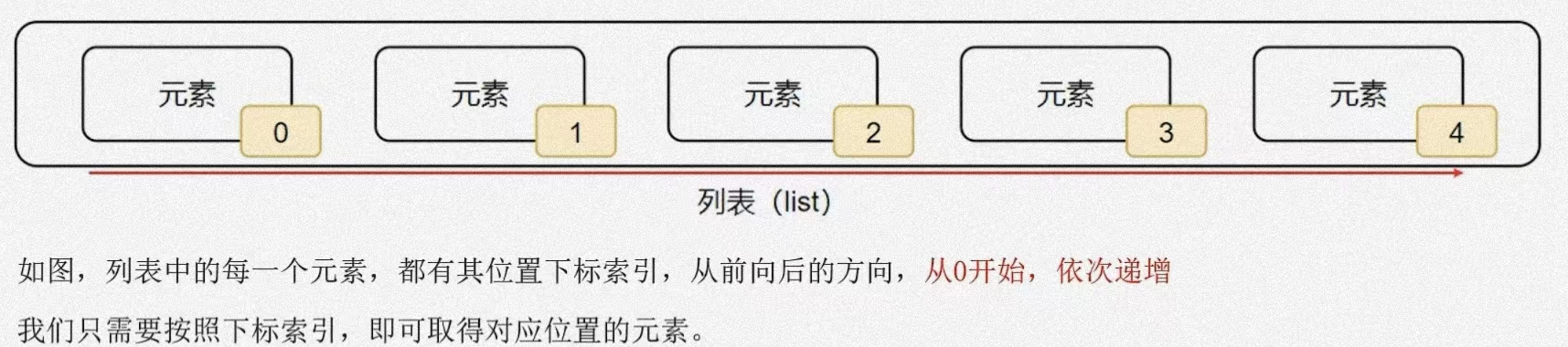
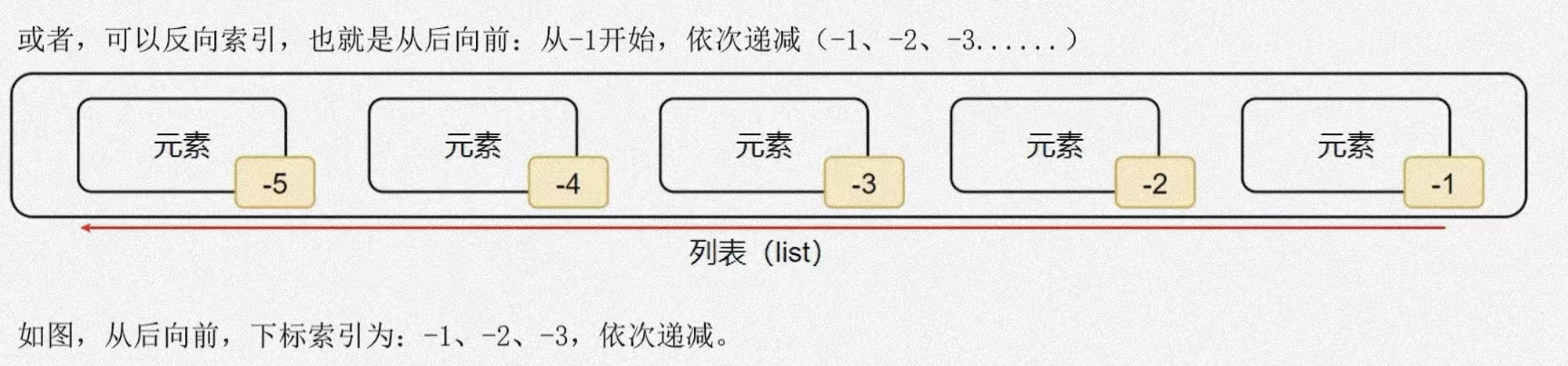
列表的索引
- 列表索引取出元素的表达式:list[索引元素位置]
- 方式有两种:从左到右的索引和从右到左的位置索引
- 第二种方法(从右往左):
list_1=['Amy','Jion','Syri','Cily']
print(f'按照位置顺序取出列表的元素1号(从左往右):{list_1[1]}',f'当然也可以从右往左边取为:{list_1[-3]}')
按照位置顺序取出列表的元素 1 号 (从左往右):Jion 当然也可以从右往左边取为:Jion
列表的拼接
-
表达式 1:list1+=[要放入的元素]
-
表达式 2:list1=list1+list2
list_1=[1,2,3] list_2=[4,5,6] #方式1 list_1+=list_2 print(f'加入后的新list_1列表为:{list_1}') #方法2 list_3=[1,2,3]+[4,5,6] print(f'加入后的新list_3列表为:{list_3}')加入后的新 list_1 列表为:[1, 2, 3, 4, 5, 6]
加入后的新 list_3 列表为:[1, 2, 3, 4, 5, 6]
嵌套列表
生成
-
表达式:nest_list=[list1,list2,list3,…]
-
使用嵌套列表即在列表里创建其它列表
list_1=[1,2,3] list_2=[4,5,6] nest_list=[list_1,list_2] #生成嵌套列表 print(f'嵌套列表为:{nest_list}')嵌套列表为:[[1, 2, 3], [4, 5, 6]]
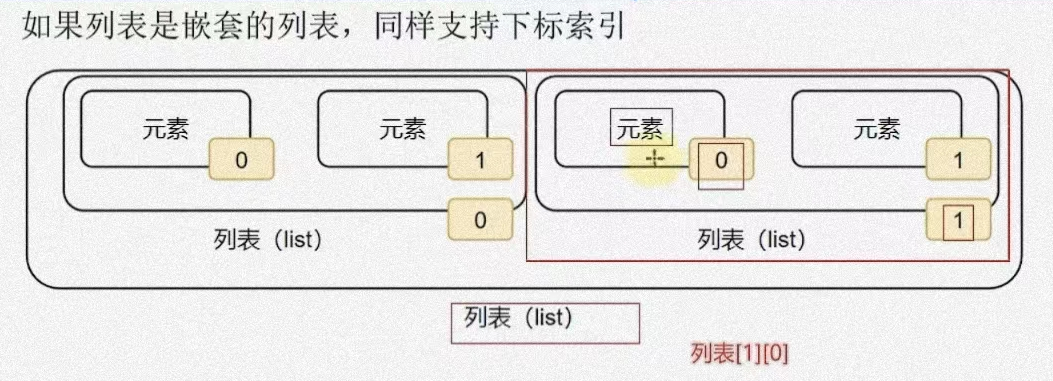
索引
- 多层嵌套列表要取出元素时的表达式:list[第一层列表所在的位置][第二层列表里元素所在的位置]…
- 注意:要是索引位置的时候超出取值范围是无法取出元素的,并且会报错
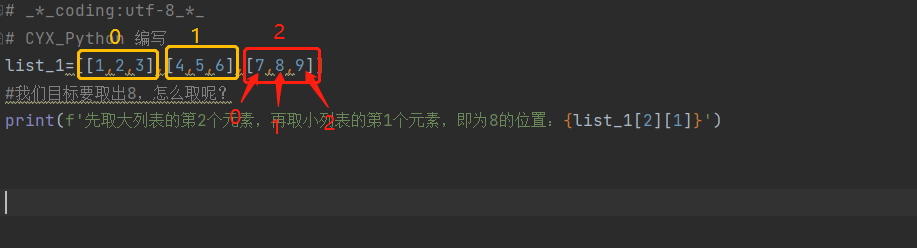
例如
list_1=[[1,2,3],[4,5,6],[7,8,9]]
#我们目标要取出8,怎么取呢?
print(f'先取大列表的第2个元素,再取小列表的第1个元素,即为8的位置:{list_1[2][1]}')
先取大列表的第 2 个元素,再取小列表的第 1 个元素,即为 8 的位置:8
列表的切片
-
表达式:list[N:M]
-
作用:能够获取一系列的元素
- 注意:列表的切片是左闭右开的
list_1=['元素','A',666,True] print(f'获取A到666的切片:{list_1[1:3]}')获取 A 到 666 的切片:[‘A’, 666]
列表的方法
- 方法的调用:方法名. 函数名 (传入参数)
回忆:函数是一个封装的代码单元,可以提供特定功能。在 Python 中,如果将函数定义为 class(类) 的成员,那么函数会称之为:方法

查询功能
-
表达式:list.index(具体的元素)
-
作用:找元素目标的所在位置,若找不到(索引位置超出范围等),则会报错
list_1=['元素','A',666] #目标为取出666 print(f'查看666在列表中所在的位置是:{list_1.index(666)}')查看 666 在列表中所在的位置是:2
修改功能
-
表达式:list[元素所在位置]= 值
-
作用:对元素目标的值进行重新赋值修改
list_1=['元素','A',666,True] #目标为修改A为B,修改True为False list_1[1]='B' list_1[-1]=False print(f'修改后的列表为:{list_1}')修改后的列表为:[‘元素’, ‘B’, 666, False]
插入元素
-
表达式:list.insert( 元素所在位置, 插入指定的元素
-
作用:在所需要的位置插入目标元素,插入后面的其余元素默认往后退一个位置
list_1=['元素','A',666,True] #在第2个位置上插入一个元素 list_1.insert(2,'插入的元素') print(f'插入元素后的列表变更位:{list_1}')插入元素后的列表变更位:[‘元素’, ‘A’, ‘插入的元素’, 666, True]
追加元素
-
表达式:list.append(追加的元素)
-
作用:将指定元素追加到列表的尾部(注意是尾部)
list_1=['元素','A',666,True] #追加一个新的元素在列表的尾部 list_1.append('我是新元素') print(f'使用append方法后的新列表:{list_1}')使用 append 方法后的新列表:[‘元素’, ‘A’, 666, True, ‘我是新元素’]
-
法二:list.extend(其他数据容器)
-
作用:extend 的方法与 append 的方法不同,extend 是将其他的数据容器的内容取出,然后依次追加到列表尾部
list_1=['元素','A',666,True] #在list_1里面追加其他列表 list_2=['我是','追加的','的元素'] list_1.extend(list_2) print(f'将list_2列表加到list_1列表里后的成为新的列表:\n{list_1}')将 list_2 列表加到 list_1 列表里后的成为新的列表:
[‘元素’, ‘A’, 666, True, ‘我是’, ‘追加的’, ‘的元素’]
删除元素
-
法一:del list[要删除元素的位置] 注意:这里是 [], 与 pop 的符号不同,要留心
- del 是直接删除要目标元素,然后得到一个新列表,无法再获得目标元素
- del 可以删除二维矩阵列表的特定元素
list_1=['元素','A',666,True] #通过del删除666 del list_1[2] print(f'通过del删除后的新列表为:{list_1}') -------------------------------------------- list_1=[[1,2,3],[4,5,6],[7,8,9]] #通过del可以删除二维矩阵列表的特定元素,比如7 del list_1[2][0] print(f'通过del删除后的的新列表为:{list_1}')通过 del 删除后的新列表为:[‘元素’, ‘A’, True]
通过 del 删除后的的新列表为:[[1, 2, 3], [4, 5, 6], [8, 9]]
-
法二:list.pop(要删除元素的位置) 注意:这里是 ()
- pop 是通过把要删除元素目标先取出来,然后再得到一个新列表,取出来的元素还可以利用
- 注意:pop 无法删除嵌套列表里的特定元素,只能删除嵌套列表
list_1=[[1,2,3],[4,5,6],[7,8,9]] #通过pop方法取出数字7 take_element=list_1.pop(2) print(f'通过pop取出来的嵌套列表为:{take_element}\n删除后得到的新二维矩阵列表为:{list_1}')通过 pop 取出来的嵌套列表为:[7, 8, 9]
删除后得到的新二维矩阵列表为:[[1, 2, 3], [4, 5, 6] -
法三:list.remove(要删除的元素) 注意:这里也是 ()
- 作用:remove 的方法是删除某元素在列表的第一个匹配项
- 一个代码只能删除一个元素,不能同时删除多个元素
list_1=['你好',666,'abc','你好',666,'abc'] #删除元素666 list_1.remove(666) print(f'删除第一个匹配项后的新列表:{list_1}')删除第一个匹配项后的新列表:[‘你好’, ‘abc’, ‘你好’, 666, ‘abc’]
清空列表
-
表达式:list.clear()
-
作用:用于清空列表内容,功能类似于 del list[:]
-
返回值:[]
list_1=[[1,2,3],[4,5,6],[7,8,9]] #清空列表 list_1.clear() print(f'通过clear清空列表内容为空列表:{list_1}') list_2=[[1,2,3],[4,5,6],[7,8,9]] del list_2[:] print(f'通过del的切片格式清除后的列表也为空列表:{list_2}')通过 clear 清空列表内容为空列表:[]
通过 del 的切片格式清除后的列表也为空列表:[]
统计元素
-
表达式:list.count(要统计的元素)
-
作用:统计某元素在列表的数量
- 一样的,该方法一个代码也只能统计一次,要统计多个元素的数量,需要使用多次该代码,或者用循环
list_1=[] for i in range(3): list_1.append('元素') for j in range(2): list_1.append(666) print(f'list_1列表的内容为:{list_1}' f'\n统计在列表里面666的数量为:{list_1.count(666)}')list_1 列表的内容为:[‘元素’, 666, 666, ‘元素’, 666, 666, ‘元素’, 666, 666]
统计在列表里面 666 的数量为:6 -
表达式:len(列表名)
- len 是老朋友了,这里可以统计列表里有多少元素
list_1=[] for i in range(3): list_1.append('元素') for j in range(2): list_1.append(666) print(f'list_1列表的内容为:{list_1}' f'\n列表内的元素数量为:{len(list_1)}')list_1 列表的内容为:[‘元素’, 666, 666, ‘元素’, 666, 666, ‘元素’, 666, 666]
列表内的元素数量为:9
元素排序
-
表达式:list.sort(cmp,key,False)
- 参数 cmp: 可选参数, 如果指定了该参数会使用该参数的方法进行排序(python 中 3.x 版本已不存在该函数 )
- 参数 key:主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序
- 参数 reserve:默认为 False,表示升序排序;如果设置为 True,表示为降序排序
list_1=[7,6,4,7,5,21,3,9] #先进行升序排序 list_1.sort() print(f'升序排序的结果为:{list_1}') #然后再进行降序排序 list_1.sort(reverse=True) print(f'降序排序的结果为:{list_1}')升序排序的结果为:[3, 4, 5, 6, 7, 7, 9, 21]
降序排序的结果为:[21, 9, 7, 7, 6, 5, 4, 3]
列表的推导式
- 推导式:[表达式 for 迭代变量 in 可迭代对象 if 条件表达式]
- 此格式中,**[if 条件表达式]** 不是必须的,可以使用,也可以省略
通过列表推导式的语法格式,明显会感觉到它和 for 循环存在某些关联。其实,除去 [if 条件表达式] 部分,其余各部分的含义以及执行顺序和 for 循环是完全一样的(表达式其实就是 for 循环中的循环体)
for 迭代变量 in 可迭代对象
表达式
它只是对 for 循环语句的格式做了一下简单的变形,并用 [] 括起来而已,只不过最大的不同之处在于,列表推导式最终会将循环过程中,计算表达式得到的一系列值组成一个列表
比如:用 for 循环计算 30 以内可以被 3 整除的整数
#这是用for循环得到的数,再添加到列表里面
list_1=[]
for i in range(31):
if i%3==0:
list_1.append(i)
print(f'用for循环后再添加到列表里面:{list_1}')
#用推导式可以快速得到一个用列表把这些数储存起来的新数据容器
list_2=[i for i in range(31) if i%3==0]
print(f'用推导式得到的列表为:{list_2}')
用 for 循环后再添加到列表里面:[0, 3, 6, 9, 12, 15, 18, 21, 24, 27, 30]
用推导式得到的列表为:[0, 3, 6, 9, 12, 15, 18, 21, 24, 27, 30]
再写一个例子:过滤掉长度小于或等于 3 的字符串列表,并将剩下的转换成大写字母
names = ['Bob','Tom','alice','Jerry','Wendy','Smith']
gain_correct_name=[]
#correct_name是可迭代变量,name为可迭代对象
for correct_names in names:
if len(correct_names)>3: #淘汰掉新变量里名字长度大于3的对象
correct_names=correct_names.upper() #将淘汰过名字的新变量进行全部字母大写化再重新赋值给自己
gain_correct_name.append(correct_names)#将过滤后得到的大写化的名字添加到列表里
print(f'得到的新变量含有的元素有:{gain_correct_name}')
#用推导式将他们装进容器里
gain1_correct_name=[correct_names.upper() for correct_names in names if len(correct_names)>3]
print(f'用推导式把for循环里要求的变量装到列表里:{gain1_correct_name}')
得到的新变量再存储到列表里含有的元素有:[‘ALICE’, ‘JERRY’, ‘WENDY’, ‘SMITH’]
用推导式把 for 循环里要求的变量装到列表里:[‘ALICE’, ‘JERRY’, ‘WENDY’, ‘SMITH’]
多层嵌套推导式
-
推导式:[表达式 for 迭代变量 in 可迭代对象 for 迭代变量 in 可迭代对象 for 迭代变量 in 可迭代对象 … if 条件表达式]
- 此格式中,**[if 条件表达式]** 不是必须的,可以使用,也可以省略
- for 迭代变量 in 可迭代对象在推导式中也可以多次嵌套
#用多层嵌套式生成多层嵌套列表 list_1=[[x,y,z] for x in range(1,2) for y in range(3) for z in range(4) ] print(f'用多层嵌套推导式生成的列表为:{list_1}') #原型 list_2=[] for x in range(1,2): for y in range(3): for z in range(4): list_2.append([x,y,z]) print(f'用原型生成的多层嵌套的列表为:{list_2}')用多层嵌套推导式生成的列表为:[[1, 0, 0], [1, 0, 1], [1, 0, 2], [1, 0, 3], [1, 1, 0], [1, 1, 1], [1, 1, 2], [1, 1, 3], [1, 2, 0], [1, 2, 1], [1, 2, 2], [1, 2, 3]]
用原型生成的多层嵌套的列表为:[[1, 0, 0], [1, 0, 1], [1, 0, 2], [1, 0, 3], [1, 1, 0], [1, 1, 1], [1, 1, 2], [1, 1, 3], [1, 2, 0], [1, 2, 1], [1, 2, 2], [1, 2, 3]]
换行算法
-
这里有个很有趣的算法,我一直想弄一个每输出 n 个元素就进行一次换行的代码,现在终于找到了解决办法
list_1=[[x,y,z] for x in range(1,2) for y in range(3) for z in range(4) ] print(f'用多层嵌套推导式生成的列表为:') #以下是最重要的代码公式,下面进行解析一下 j=0 #首先,这里设置了初始值是j为0 for i in list_1: #然后让i进行遍历list_1列表,此时i获得了list_1列表里的所有元素,如何让这些元素进行每n个输出便换行是一个问题 print(i,end='\t') #这里是先让i变量里所有的元素都进行一个横向的排列 j=j+1 #这里是重点,此时i每遍历list_1里的元素,这里的j就会进行+1然后重新赋值给j,此时的j可以看作是与i遍历次数是相同的,即当i进行k次遍历时,此时j=k if j%4==0: #这里也是重点,这里是决定每输出n个元素就决定进行的一次换行操作,当j%n等于0时,下面就可以print()来进行换行了,显然这里是每输出4个元素就进行一次换行 print()用多层嵌套推导式生成的列表为:
[1, 0, 0] [1, 0, 1] [1, 0, 2] [1, 0, 3]
[1, 1, 0] [1, 1, 1] [1, 1, 2] [1, 1, 3]
[1, 2, 0] [1, 2, 1] [1, 2, 2] [1, 2, 3] -
简单算法举例
- 要求:将两个列表中的数值按“能否整除”的关系配对在一起
list_a= [2,3] list_b= [30, 12, 66, 34, 39, 78, 36, 57, 121] result_list=[(x,y) for x in list_a for y in list_b if y%x==0] print(f'能够整除后得到的配对数的列表为:{result_list}')能够整除后得到的配对数的列表为:[(2, 30), (2, 12), (2, 66), (2, 34), (2, 78), (2, 36), (3, 30), (3, 12), (3, 66), (3, 39), (3, 78), (3, 36), (3, 57)]
max 和 min 函数
-
max 函数表达式:max(lsit)
- 作用:返回列表元素中的最大值
- 如果列表中存储的元素全是数字类型,则返回列表中最大的数字
- 如果列表中存储的元素全是字符串类型,则返回的是对应 ASCII 最大的字符
- 作用:返回列表元素中的最大值
-
min 函数表达式:min(list)
- 作用:作用:返回列表元素中的最小值
- 如果列表中存储的元素全是数字类型,则返回列表中最小的数字
- 如果列表中存储的元素全是字符串类型,则返回的是对应 ASCII 最小的字符
list_1=[51,34,200] print(f'返回最大的数值为:{max(list_1)},返回最小的数值为:{min(list_1)}')返回最大的数值为:200, 返回最小的数值为:34
- 作用:作用:返回列表元素中的最小值
元组 (tuple)
元组和列表一样,都可以封装多个、不同类型的元素在内,但元组一旦定义完成,就不可以修改 (即不能直接增加或删除元素)
元组的特点:有序、任意数量元素、允许重复元素
定义:元组可以使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型
元组变量名称 = (元素 1, 元素 2, 元素…)
空元组
变量名称 = () #方式 1
变量名称 = tuple() #方式 2
注意:如果元组只有一个数据,这个数据后面要添加逗号,否则,它就不是元组类型
tuple = (“hello”,)
元组的嵌套
tuple = (( 元素 1, 元素 2, …), (元素 1, 元素 2, …) )
元组元素的索引
语法
元组变量名 [第一层元素下标 1][第二层元素下标 2]…
t1 = ((1, 2, 3), (4, 5, 6))
print(f"取到的元素是:{t1[1][2]}")
取到的元素是:6
索引下标方法
语法
元组变量名.index(元组里的某个元素)
作用:查找某个数据,如果数据存在则返回对应的下标,否则报错
t1 = ((1, 2, 3), (4, 5, 'Hello'))
print(f"Hello的索引位置为:{t1[1].index('Hello')}")
Hello 的索引位置为:2
统计次数方法
语法
元组变量名.count(元组里的某个元素)
作用:统计某个数据在元组出现的次数
t1 = ((1, 5, 3), (5, 5, 'Hello'))
print(f"‘5’在第1层嵌套元组出现的次数为:{t1[1].count(5)}次")
‘5’在第 1 层嵌套元组出现的次数为:2 次
统计元素个数
语法
len(元组变量名)
作用:统计元组内的元素个数
t2 = (1, 2, 3, 4, 5, 6, 7)
print(f"元组里元素的个数为:{len(t2)}")
元组里元素的个数为:7
元组的遍历
t2 = ('Timi', 2333, 6.66, ('嘿嘿嘿',3), ['列表',4], {'字典':5}, 7
#第一种写法:
for i in range(len(t2)):
print(f"元组里的元素有:{t2[i]}")
#第二种写法:
for element in t2:
print(f"元组里的元素有:{element}")
元组里的元素有:Timi
元组里的元素有:2333
元组里的元素有:6.66
元组里的元素有:(‘嘿嘿嘿’, 3)
元组里的元素有:[‘列表’, 4]
元组里的元素有:{‘字典’: 5}
元组里的元素有:7
元组元素的修改
要实现元组元素的修改得先将元组转化为列表,通过列表修改元素,然后再将列表转回为元组
元组转化为列表
list(元组变量名)
列表转化为元组
tuple(列表变量名)
tuple1 = ('Timi', 2333, 6.66, ('嘿嘿嘿',3), ['列表',4], {'字典':5}, 6)
list1 = list(tuple1) #元组转化为列表
list1[6] = "修改的元素" #将列表的第6个元素进行修改
tuple1 = tuple(list1) #再将列表转化为元组,这样就把元组里的元素给修改了
for element in tuple1:
print(f"修改后的元组里的元素有:{element}")
修改后的元组里的元素有:Timi
修改后的元组里的元素有:2333
修改后的元组里的元素有:6.66
修改后的元组里的元素有:(‘嘿嘿嘿’, 3)
修改后的元组里的元素有:[‘列表’, 4]
修改后的元组里的元素有:{‘字典’: 5}
修改后的元组里的元素有:修改的元素
特例
如果元组里面嵌套了列表,那么该列表的元素是可以修改的,具体为:先取到该列表,然后再改列表里的元素
元组变量名 [嵌套列表的下标][嵌套列表里要修改的元素的下标] = 修改值
tuple1 = ('Timi', 2333, 6.66, ('嘿嘿嘿',3), ['列表',4], {'字典':5}, 6)
tuple1[4][0] = '我是列表'
print(f"元组里的嵌套列表的元素变为:{tuple1[4]}")
元组里的嵌套列表的元素变为:[‘我是列表’, 4]
字符串 (string)
字符串也是数据容器的一员,字符串里面的每一个字符就是一个元素,且字符串同元组一样,是一个无法修改的数据容器,
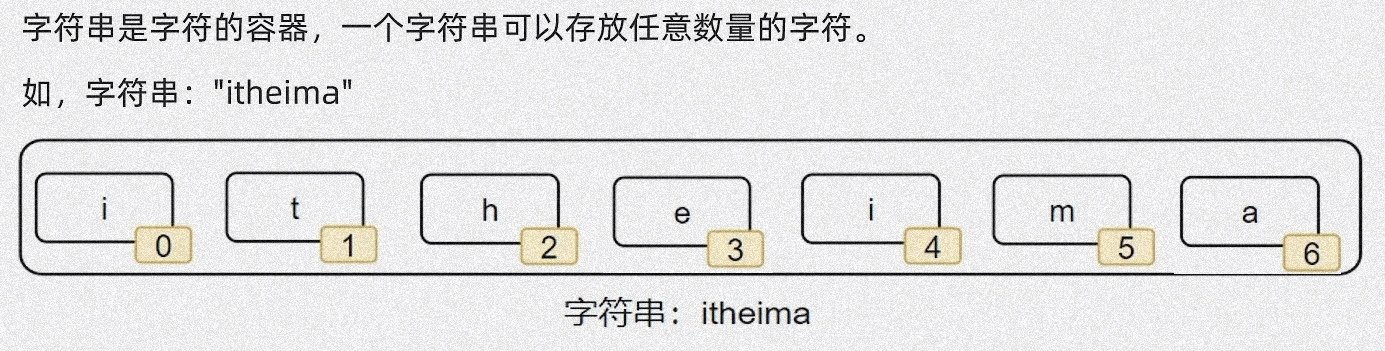
字符串的索引:从前向后,下标从 0 开始;从后向前,下标从 -1 开始
字符串的语法
| 作用 | 语法 | 例子:str = “Tim and King” |
|---|---|---|
| 查找特定字符串的下标索引值 | 字符串变量名.index(要索引的字符串 / 字符) | str.index(“and”) #起始下标为 4 |
| 字符串的替换 (最终得到的是一个新字符串) | 字符串变量名.replace(要被替换的字符串, 替换成的字符串) | new_str = str.replace(“Tim”,“Tom”) |
| 按照指定的分隔字符串,将字符串划分为多个字符串,并存入列表对象中 (字符串本身不变,而是得到了一个列表对象) | 字符串变量名.split(分隔符字符串). | str_list = str.split(" ")[空格分隔] |
| 去除字符串前后的空格或换行符 | 字符串变量名.strip() | new_str = str.strip() |
| 去除字符串前后指定的字符 (若前或后没遇到指定字符则停止去除) | 字符串变量名.strip(字符串) | new_str = str.strip(“Tngi”) #m and K |
| 统计字符串中某字符串的出现次数 | 字符串变量名.count(某字符串) | times = str.count(“i”) #2 次 |
| 统计字符串的长度 | len(字符串变量名) | length = len(str) #12 |
字符串特点
- 只可以存储字符串
- 长度任意(取决于内存大小)
- 支持下标索引
- 允许重复字符串存在
- 不可以修改(增加或删除元素等)
- 支持 for、while 等的循环
序列的操作
序列是指:内容连续、有序、可以使用下标索引的一类数据容器。(列表、元组、字符串,均可以视为序列)

序列支持切片,即:列表、元组、字符串,均支持进行切片操作
切片
切片:从一个序列中,取出一个子序列的操作
语法
序列 [起始下标 : 结束下标 : 步长] [起始 , 结束) 左闭右开
- 起始下标:表示从何处开始,可以留空,当留空时视作从头开始作为起始下标
- 结束下标:(不含结束下标,实际为结束下标的上一位),表示从何处结束,可以留空,当留空时视作从起始下标截取到序列的结尾
- 步长:表示依次每次取目标元素之间的其他元素间隔数
- 步长 1:表示一个一个取元素
- 步长 2:表示每次跳过 1 个元素取目标元素
- 步长 N:每次跳过 N-1 个元素取目标元素
- 步长为负数表示,倒序执行 (起始下标和结束下标也要反向标记)
从头到尾去取元素
字符串名 / 列表名 / 元组名 [:]
list_ = [0, 1, 2, 3, 4, 5, 6]
#以2为步长每次跳过1个元素取list里的目标元素
print(list_[0:7:2])
string = "Hello World"
#全取string里的元素
print(string[:])
tuple_ = (10001, 10002, 10003, 10004)
#以最后一个元素倒序-1为结尾元素取目标元素,这意味着取不到最后一个元素,左闭右开
print(tuple_[-3:-1])
[0, 2, 4, 6]
Hello World
(10002, 10003)
集合 (set)
集合的定义
集合不支持元素的重复 (自带去重功能),且集合内元素无序,即不支持元素下标索引访问,但集合支持修改,集合的符号为:{}
定义集合
{元素 1, 元素 2, 元素 3, …}
定义集合变量
集合名 = {元素 1, 元素 2, 元素 3, …}
set_ = {"Tom","King","Tom","King","Mary"}
#集合不支持重复的元素,且每次运行顺序不一样
print(set_)
{‘Mary’, ‘Tom’, ‘King’}
-------------- 第二次运行 -------------
{‘Tom’, ‘King’, ‘Mary’}
定义空集合
集合名 = set()
集合的方法
追加元素
集合.add(新元素)
- 将指定元素添加到集合内,结果集合本身被修改
set_ = {"Tom","King","Tom","King","Mary"}
#add添加元素
set_.add("Timi")
print(set_)
{‘Mary’, ‘Timi’, ‘Tom’, ‘King’}
移除元素
集合.remove(旧元素)
- 将指定元素,从集合内移除,结果集合本身被修改
set_ = {"Tom","King","Tom","King","Mary"}
#remove移除指定旧元素
set_.remove("King")
print(set_)
{‘Tom’, ‘Mary’}
随机取出元素
集合.pop()
- 从集合中随机取出一个元素,可以得到这个元素,同时集合本身被修改,元素被移除
set_ = {"Tom","King","Tom","King","Mary"}
#pop随机移除元素,得到移除的元素
element = set_.pop()
print(element)
#再次查看集合的元素
print(set_)
Mary
{‘King’, ‘Tom’}------- 第二次运行 -------
Tom
{‘Mary’, ‘King’}
清空集合
集合.clear()
- 清空集合里的所有元素,集合本身被清空
set_ = {"Tom","King","Tom","King","Mary"}
#clear清空集合
set_.clear()
#再次查看集合,结果为set(),表示空集合
print(set_)
set() <---- 表示空集合
集合的差集
新集合 3 = 集合 1.difference(集合 2)
- 取出集合 1 有但是集合 2 没有的元素,最后得到一个新集合,集合 1 和集合 2 不变
set1 = {1, 2, 3} #集合1有2,3
set2 = {1, 4, 5} #集合2没有2,3
#difference取差集,取出集合1有但是集合2没有的元素,最后得到一个新集合,集合1和集合2不变
set3 = set1.difference(set2)
print(f"得到一个新集合:{set3}")
得到一个新集合:{2, 3}
集合的更新
要更新的集合 1.difference_update(参考的集合 2)
- 在集合 1 中,删除集合 1 和集合 2 中共有的元素 (集合 1 被修改,集合 2 不变)
set1 = {1, 2, 3}
set2 = {1, 4, 5}
#difference_update,将集合1和集合2共有的元素删除,集合1被修改,集合2不变
set1.difference_update(set2)
print(f"集合1被修改后为:{set1}")
集合 1 被修改后为:{2, 3}
集合的合并
新集合 3 = 集合 1.union(集合 2)
- 得到一个新集合,内含 2 个集合的全部元素,原有的 2 个集合内容不变
set1 = {1, 2, 3}
set2 = {1, 4, 5}
#新集合3 = 集合1.union(集合2),得到一个新集合,内含2个集合的全部元素,原有的2个集合内容不变
set3 = set1.union(set2)
print(f"两集合合并后的新集合3为:{set3}")
两集合合并后的新集合 3 为:{1, 2, 3, 4, 5}
- len(集合) – ,得到一个整数,为该集合中的元素的数量
字典 (dict)
字典的特点:
- 字典内的 key 不允许重复,重复添加等同于覆盖原有数据
- 可以容纳不同类型的数据
- 每一份数据都是 KeyValue 的键值对
- 不支持下标索引,字典的元素可以修改,新增,支持 for 循环,不支持 while 循环
字典的定义:生活中的字典是通过字去找到该字的含义,python 中的字典是通过 key 字去找到对应的 value 值 (key : value)
字典也是使用 {},但里面存储的是一个一个的键值对:(key : value),不同键值对之间用英文逗号连接
定义字典
字典名 = {key1: value1 ,key2: value2 , …}
定义空字典
方法 1:
字典名 = {}
方法 2:
字典名 = dict()
dict1 = {"周杰伦": "18岁", "王力宏": 18}
print(f"字典的内容为:{dict1}")
字典的内容为:{‘周杰伦’: ‘18 岁’, ‘王力宏’: 18}
key 重复的字典
python 中的字典的 key 重复时,前面的相同的 key 的键值对会被最后面的一个覆盖
dict1 = {"周杰伦": "18岁", "王力宏": 18, "周杰伦": "歌手"}
print(f"字典的内容为:{dict1}")
字典的内容为:{‘周杰伦’: ‘歌手’, ‘王力宏’: 18}
字典数据的获取
字典通集合一样,不可以使用下标索引,但是字典可以通过 key 名来取得对应的 value
value 值 = 字典名 [key 名]
- #注意使用 f"输出内容" 格式时,字典的 key 必须使用单引号去获取内容 (字典名 [‘key 名’]),用双引号会报错
dict1 = {"周杰伦": "18岁", "王力宏": 18, "林俊杰": "歌手"}
#字典可以通过key名来取得对应的value,value值 = 字典名[key名]
#林俊杰的value为"歌手"
value = dict1["林俊杰"]
#注意使用f""格式时,字典的key必须使用单引号去获取内容(字典名['key名']),用双引号会报错
print(f"周杰伦的value为:{dict1['周杰伦']}\n王力宏的value为:{dict1['王力宏']}\n林俊杰的value为:{value}")
周杰伦的 value 为:18 岁
王力宏的 value 为:18
林俊杰的 value 为:歌手
字典的嵌套
字典的 key 和 value 可以是任意数据类型 (key 不可以为字典,value 无任何限制)
dict2 = {"周杰伦": {"职业": "歌手", "年龄": 18, "性格": "文雅"},
"王力宏": {"职业": "演员", "年龄": 20, "性格": "温柔"},
"林俊杰": {"职业": "歌手", "年龄": "30岁", "性格": "和蔼"}}
print(f"嵌套字典的内容为:{dict2}")
嵌套字典的内容为:{‘周杰伦’: {‘职业’: ‘歌手’, ‘年龄’: 18, ‘性格’: ‘文雅’}, ‘王力宏’: {‘职业’: ‘演员’, ‘年龄’: 20, ‘性格’: ‘温柔’}, ‘林俊杰’: {‘职业’: ‘歌手’, ‘年龄’: ‘30 岁’, ‘性格’: ‘和蔼’}}
嵌套字典的 value 获取
value 值 = 字典名 [第一层字典的 key 名][第一层 value 值的第一层字典的 key 名][第二层 value 值的第二层字典的 key 名][…]
dict2 = {"周杰伦": {"职业": "歌手", "年龄": 18, "性格": "文雅"},
"王力宏": {"职业": "演员", "年龄": 20, "性格": "温柔"},
"林俊杰": {"职业": "歌手", "年龄": "30岁", "性格": "和蔼"}}
print(f"周杰伦的职业为:{dict2['周杰伦']['职业']}\n"
f"王力宏的性格为:{dict2['王力宏']['性格']}\n"
f"林俊杰的年龄为:{dict2['林俊杰']['年龄']}")
周杰伦的职业为:歌手
王力宏的性格为:温柔
林俊杰的年龄为:30 岁
新增元素
字典名 [新 key 名] = 新 value 值
- 在原有字典的基础上新增元素
dict1 = {"周杰伦": "18岁", "王力宏": 18, "林俊杰": "歌手"}
# 新增字典名[key名] = value值
dict1["路飞"] = "船长"
print(dict1)
{‘周杰伦’: ‘18 岁’, ‘王力宏’: 18, ‘林俊杰’: ‘歌手’, ‘路飞’: ‘船长’}
更新 value 值
字典名 [字典上已有的 key 名] = 新 value 值
- 字典 key 不可以重复,所以对已存在的 key 执行上述操作,就是更新 value 值
dict1 = {"周杰伦": "18岁", "王力宏": 18, "路飞": "船长"}
# 更新字典:字典名[字典上已有的key名] = 新value值
dict1["周杰伦"] = "歌手"
print(dict1)
{‘周杰伦’: ‘歌手’, ‘王力宏’: 18, ‘路飞’: ‘船长’}
删除元素
value 值 = 字典名.pop(字典上已有的 key 名)
- 获得指定 key 的 value 值,在原有字典的基础上删除指定 key 的数据
dict1 = {"周杰伦": "18岁", "王力宏": 18, "路飞": "船长"}
# 删除元素:value值 = 字典名.pop(字典上已有的key名)
value_ = dict1.pop("路飞")
print(f"将删除的key存的value值取出:{value_}\n"
f"得到的新字典为:{dict1}")
将删除的 key 存的 value 值取出:船长
得到的新字典为:{‘周杰伦’: ‘18 岁’, ‘王力宏’: 18}
清空字典
字典名.clear()
- 原有字典的所有元素都被清空
dict1 = {"周杰伦": "18岁", "王力宏": 18, "路飞": "船长"}
# 清空字典:字典名.clear()
dict1.clear()
print(f"清空字典后得到一个空字典:{dict1}")
清空字典后得到一个空字典:{}
获取字典全部的 key
字典名.keys()
- 得到字典中的全部的 key,但是无 value 值
dict1 = {"周杰伦": "18岁", "王力宏": 18, "路飞": "船长"}
# 获取字典全部的key:字典名.keys()
print(f"获取字典全部的key:{dict1.keys()}"
f"\n该类型为:{type(dict1.keys())}")
获取字典全部的 key:dict_keys([‘周杰伦’, ‘王力宏’, ‘路飞’])
该类型为:<class ‘dict_keys’>
通过 key 遍历字典
可以通过 == 字典名.key()== 在拿到字典的所有 key 后,通过 key 去遍历字典从而取到 value 值
dict1 = {"周杰伦": "18岁", "王力宏": 18, "路飞": "船长"}
# 获取字典全部的key:字典名.keys()
for key in dict1.keys():
print(f"通过该方法获取的key名有:{key} ",end="\t")
print(f"通过key名拿到的字典的value值为:{dict1[key]}")
通过该方法获取的 key 名有: 周杰伦 通过 key 名拿到的字典的 value 值为:18 岁
通过该方法获取的 key 名有: 王力宏 通过 key 名拿到的字典的 value 值为:18
通过该方法获取的 key 名有: 路飞 通过 key 名拿到的字典的 value 值为:船长
优化写法:直接通过字典名遍历就行了,通过字典名遍历也是一样都拿到的 key 值
dict1 = {"周杰伦": "18岁", "王力宏": 18, "路飞": "船长"}
# 直接 in 字典名 就行了
for key in dict1:
print(f"通过该方法获取的key名有:{key} ",end="\t")
print(f"通过key名拿到的字典的value值为:{dict1[key]}")
通过该方法获取的 key 名有: 周杰伦 通过 key 名拿到的字典的 value 值为:18 岁
通过该方法获取的 key 名有: 王力宏 通过 key 名拿到的字典的 value 值为:18
通过该方法获取的 key 名有: 路飞 通过 key 名拿到的字典的 value 值为:船长
统计元素数量
len(字典名)
dict1 = {"周杰伦": "18岁", "王力宏": 18, "路飞": "船长"}
# len(字典名)
print(len(dict1))
3
嵌套使用
在字典里新增元素
字典名 [f"{ 新增元素名}"] = {嵌套字典 value 值}
count = 0
employee1 = {}
while True:
count += 1
name = input("请输入名字:")
occupation = input("请输入部门:")
salary = input("请输入薪水:")
rank = input("请输入级别:")
employee1[f"{name}"] = {"部门": f"{occupation}", "工资": f"{salary}", "等级": f"{rank}"}
if count == 3:
break
print(employee1)
请输入名字:王力宏
请输入部门:科技部
请输入薪水:2000
请输入级别:1
请输入名字:路飞
请输入部门:海贼部
请输入薪水:4000
请输入级别:2
请输入名字:娜美
请输入部门:财务部
请输入薪水:3000
请输入级别:1
{‘王力宏’: {‘部门’: ‘科技部’, ‘工资’: ‘2000’, ‘等级’: ‘1’}, ‘路飞’: {‘部门’: ‘海贼部’, ‘工资’: ‘4000’, ‘等级’: ‘2’}, ‘娜美’: {‘部门’: ‘财务部’, ‘工资’: ‘3000’, ‘等级’: ‘1’}}
数据容器的特点
| 列表 list[] | 元组 tuple() | 字符串 str" " | 集合 set{} | 字典 dict{key,value} | |
|---|---|---|---|---|---|
| 元素类型 | 任意 | 任意 | 仅字符 | 任意 | key:value(key 不能为字典) |
| 下标索引 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 重复元素 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 可修改性 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| 数据有序 | 是 | 是 | 是 | 否 | 否 |
max 和 min
max 和 min 函数能直接在数据容器中找到其元素中的最大值和最小值
最大值 = max(数据容器名)
最小值 = min(数据容器名)
数据容器的转换
转为 list 数据容器
list(其他数据容器名)
- 将其他数据容器转换为列表
转为 str 字符串
str(其他数据容器名)
- 将其他数据容器转为字符串
转为 tuple 元组
tuple(其他数据容器名)
- 将其他数据容器转为元组
转为 set 集合数据容器
set(其他数据容器)
- 将其他数据容器转为集合
sorted 数据容器的排序
对指定的数据容器里面的元素进行升序排序或降序排序
sorted(数据容器名 [,reverse = boolean])
- 默认为 False,可省略,表升序排序
- reverse = True 时为降序排序
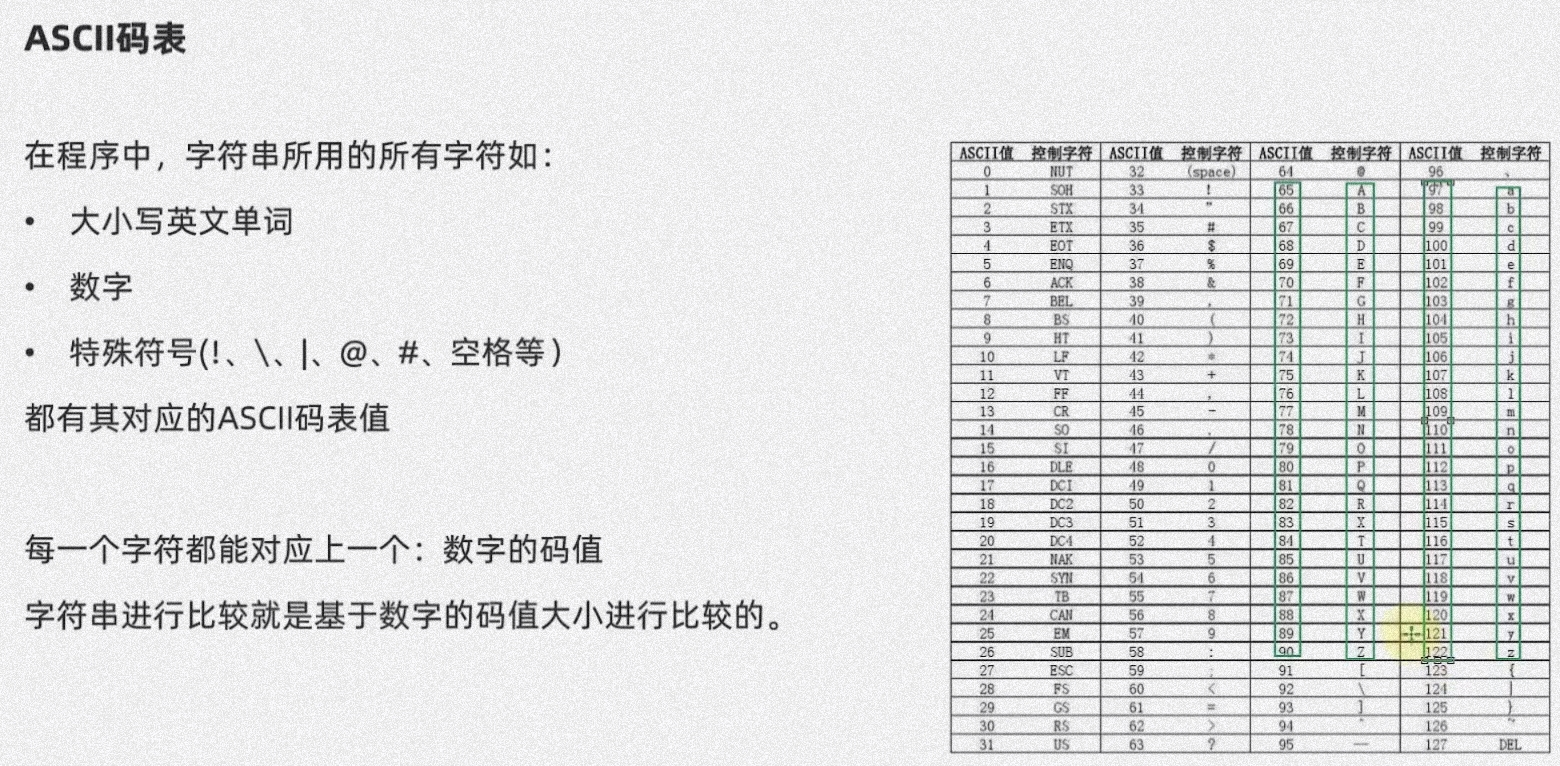
字符串大小的比较
通过 ASCII 码表比较大小
文件操作
文件编码
什么是编码?
编码就是一种规则集合,记录了内容和二进制进行相互转换的逻辑,编码有 UTF-8、GBK、Big5 等,目前最常用的编码为 UTF-8
为什么需要使用编码?
计算机只认识 0 和 1,所以需要将内容翻译成 0 和 1 才能保存在计算机中。同时也需要编码,将计算机保存的 0 和 1,反向翻译回可以识别的内容
文件的读取
文件的操作三步走:
- 打开文件
- 读写文件
- 关闭文件
open 打开文件
在 python 中可以使用 open 函数,可以打开一个已经存在的文件,或者创建一个新的文件
文件对象名 = open(“文件名所在的具体路径”, 访问模式, encoding = 编码格式)
-
文件的具体路径遇到 \ 符号时,需要加反斜杠即 \\ 才能使用,或者直接用 / 来代替文件路径中的反斜杠符号
- D:\\2011 年 1 月销售数据.txt 或者 D:/2011 年 1 月销售数据.txt
-
访问模式:只读 - "r" 、写入 - "w" 、 追加 - "a"
-
encoding = “UTF-8” – 推荐这种编码格式
| 文件的打开模式 | 描述 |
|---|---|
| ’r’ | 只读模式,默认值,如果文件不存在,返回 FileNotFoundError |
| ’w’ | 覆盖写模式,文件不存在则创建,存在则删除原有全部内容再写入 |
| ’x’ | 创建写模式,文件不存在则创建,存在则返回 FileExistsError |
| ’a’ | 追加写模式,文件不存在则创建,存在则在文件内容最后写入新的追加内容 |
| ’b’ | 二进制文件模式 |
| ’t’ | 文本文件模式,默认值 |
| ’+' | 与 r/w/x/a 一同使用,在原功能基础上增加同时读写功能 |
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新 (可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
close 关闭文件
文件对象名.close()
- 关闭文件的操作,即停止对文件的占用,如果没有使用该方法,则 open 文件后会一直占用文件使外部环境无法使用或操作该文件
- close 功能内置了 flush 的内容刷新的方法
演示案例
read 读取方法
文件对象名.read(要读取的字节长度)
- 如果没有传入要读取的字节长度,则默认读取文件的全部内容
file = open("D:\\f1.txt", "r", encoding="utf-8")
print(file.read())
当我和世界不一样
那就让我不一样
坚持对我来说
就是以刚克刚
我如果对自己妥协
如果对自己说谎
即使别人原谅
我也不能原谅
最美的愿望 一定最疯狂
我就是我自己的神
在我活的地方
我和我最后的倔强
readline 读行方法
文件对象名.readline(一行内要读取的前 n 个字节长度的内容)
- 该方法只能读取文件里的一行的内容,使用 for 循环可以读取多行内容
file = open("D:\\f1.txt", "r", encoding="utf-8")
print(f"读取一行里的前5个字节的内容:{file.readline(5)}")
当我和世界
readlines 方法
文件对象名.readlines(每行内要读取的前 n 个字节长度的内容)
- readlines() 方法是把文件内容的每一行的内容读取下来,并将每一行的内容作为一个元素存入列表中,该方法返回的是以行的内容为单位元素的列表
file = open("D:\\f1.txt", "r", encoding="utf-8")
print(file.readlines())
[‘当我和世界不一样 \n’, ‘那就让我不一样 \n’, ‘坚持对我来说 \n’, ‘就是以刚克刚 \n’, ‘我如果对自己妥协 \n’, ‘如果对自己说谎 \n’, ‘即使别人原谅 \n’, ‘我也不能原谅 \n’, ‘最美的愿望 一定最疯狂 \n’, ‘我就是我自己的神 \n’, ‘在我活的地方 \n’, ‘我和我最后的倔强 \n’]
单线程的读取记忆
f2 的文件内容
当我和世界不一样,那就让我不一样,坚持对我来说,就是以刚克刚,我如果对自己妥协,如果对自己说谎,即使别人原谅,我也不能原谅,最美的愿望 一定最疯狂,我就是我自己的神,在我活的地方,我和我最后的倔强
在同一个线程中读取文件的操作是具有记忆性的,每一次读取文件的内容都会记录下当前光标的读取位置,等到下一次读取时,则会从上一次光标所在的位置接着读取接下来的内容
file = open("D:\\f2.txt", "r", encoding="utf-8")
print(file.read(5))
print(file.read(10))
print(file.read(7))
当我和世界
不一样,那就让我不一
样,坚持对我来
with open 自动关闭
with open (“文件具体路径”, 访问模式, encoding = 编码格式) as 文件对象名:
对文件进行操作
- 该方法可以对文件进行操作完成后进行自动关闭 close 文件,避免忘记使用 close 方法在对文件进行操作完成后进行关闭的操作
with open("D:\\f1.txt", "r", encoding="utf-8") as file:
print(file.read())
当我和世界不一样
那就让我不一样
坚持对我来说
就是以刚克刚
我如果对自己妥协
如果对自己说谎
即使别人原谅
我也不能原谅
最美的愿望 一定最疯狂
我就是我自己的神
在我活的地方
我和我最后的倔强
count 统计频数
文件对象名.read().count(“要统计的元素出现的次数”)
with open("D:\\f1.txt", "r", encoding="utf-8") as file:
print(f"我在这段本文中出现的次数为:{file.read().count('我')}次")
我在这段本文中出现的次数为:10 次
write 写入文件
文件对象名.write(“要写入的内容”)
- 直接调用 write 方法时,内容并未真正写入文件,而是会积攒在程序的的内存中,称为缓冲区
- 只有当调用 flush 方法时去刷新时,要写入的内容才会真正写入文件
- 文件存在则会把文件内容全部清空再写,文件不存在则会创建再写入
文件对象名.flush()
with open("D:\\f3.txt", "w+", encoding="utf-8") as file:
#向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。
file.writelines("我要按行写入内容\n")
file.write("我要写入内容")
# 文件要写的内容完成后,使用flush方法一次性将内容写入文件
file.flush()
with open("D:\\f3.txt", "r", encoding="utf-8") as file:
#查看写入的内容
print(file.read())
我要按行写入内容
我要写入内容
writelines 列表写入
文件对象名.writelines([“要写入的内容”])
- 该方法时将字符串列表写入到文件中
with open("D:\\f4.txt", "w+", encoding="utf-8") as file:
file.writelines(["我是列表里的字符串",",可以把列表里的字符串写到文件中"])
with open("D:\\f4.txt", "r+", encoding="utf-8") as file:
print(file.read())
我是列表里的字符串,可以把列表里的字符串写到文件中
文件的追加模式
with open(“D:\f3.txt”, “a+”, encoding=“utf-8”) as file:
- 把访问模式换称 a+ 就行了
seek 移动光标
文件对象名.seek(offset, 起始移动的位置)
-
offset:表示设置文件流中的当前文件位置
-
起始移动位置为 0:表示从文件开头位置开始算起 -- 默认值为 0
-
起始移动位置为 1:表示从文件当前位置开始算起
-
起始移动位置为 2:表示从文件结尾位置开始算起
with open("D:\\f1.txt", "r", encoding="utf-8") as file:
print(file.read(9))
#重新设置当前光标为0
file.seek(0)
print(file.read())
当我和世界不一样
当我和世界不一样
那就让我不一样
坚持对我来说
就是以刚克刚
我如果对自己妥协
如果对自己说谎
即使别人原谅
我也不能原谅
最美的愿望 一定最疯狂
我就是我自己的神
在我活的地方
我和我最后的倔强
tell 返回光标位置
文件对象名.tell
- 用于返回当前光标的位置
with open("D:\\f1.txt", "r", encoding="utf-8") as file:
print(file.read(9))
print(f"当前光标的位置为:{file.tell()}")
当我和世界不一样
当前光标的位置为:26
异常
什么是异常?
- 当检测一个错误时,python 解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的异常,也就是 BUG
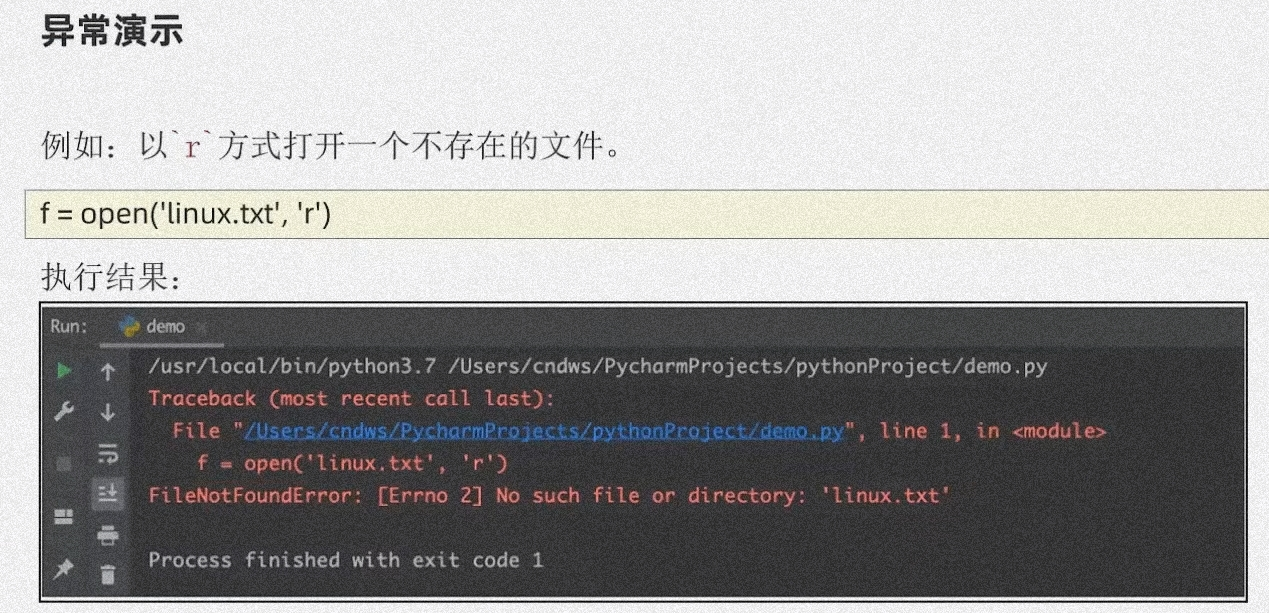
捕获异常的作用:提前假设某处会出现异常,做好提前的准备,当真的出现异常的时候,就可以有后续的手段
异常的捕获
try:
可能发生错误的代码
except:
如果出现异常就执行的代码
- 顶级异常捕获,捕获所有的异常
捕获指定的异常
try:
可能发生的错误代码
except 指定异常名 as e:
如果出现指定异常就执行的代码
- 如果指定的异常类型与捕获的异常类型不一致,则无法捕获
- 一般 try 下只放一行尝试执行的代码
try:
print(name)
except NameError as e:
print("name没有初始化定义")
name 没有初始化定义
除零异常:ZeroDivisionError ,python 中任何数都无法直接除以 0
try:
1/0
except ZeroDivisionError as e:
print("python中任何数都无法直接除以0")
------------------------------------------
try:
1/0
except NameError as e:
print("python中任何数都无法直接除以0")
python 中任何数都无法直接除以 0
1/0
ZeroDivisionError: division by zero
异常对象的原因可以输出出来
try:
1/0
except ZeroDivisionError as e:
print("python中任何数都无法直接除以0")
print(e)#输出异常的原因
python 中任何数都无法直接除以 0
division by zero
捕获多个异常
try:
可能出现多个异常的代码
except(异常名 1, 异常名 2, …):
当出现多个异常时就执行的代码
当代码出现多个异常时,程序会优先捕获第一个开始出现异常
try:
print(name) #先被捕获
1/0
except (NameError,ZeroDivisionError) as e:
print(e)
name ‘name’ is not defined
顶级异常捕获
try:
可能出现多个异常的代码
except Exception as e:
当出现多个异常时就执行的代码
- Exception 会捕获所有的异常,当然也可以省略不写
else 没有异常
如果没有异常时要执行的代码
try:
可能出现多个异常的代码
except:
当出现多个异常时就执行的代码
else:
没有异常时要执行的代码
try:
print(1)
except:
print("出现异常")
else:
print("没有出现异常时就执行else里面的代码")
1
没有出现异常时就执行 else 里面的代码
finally 必执行
finally 表示无论是否有异常最后都要执行代码
try:
可能出现多个异常的代码
except:
当出现多个异常时就执行的代码
else:
没有异常时要执行的代码
finally:
不管有没有异常都要执行的代码
- else 和 finally 可以省略
try:
print(name)
except:
print("出现异常")
else:
print("没有出现异常时就执行else里面的代码")
finally:
print("不管有没有异常都要执行finally下的代码")
出现异常
不管有没有异常都要执行 finally 下的代码
异常的传递性

处理方法 1:可以直接在顶级报错里面捕获传递性的异常 [python]
处理方法 2:可以在报错的最下面找到报错的源头,然后再处理异常 [python]
Python 的模块
什么是模块?
- Python 模块 (Module),是一个 Python 文件,以.py 结尾,模块能定义函数,类和变量,模块里也能包含可执行的代码
模块的作用:
- python 中有很多各种不同的模块,每一个模块都可以快速的实现一些功能,比如实现和时间相关的功能就可以使用 time 模块,因此可以认为一个模块就是一个工具包 (python 的模块相当于 java 的包),每一个工具包中都有各种不同的工具可以使用进而实现各种不同的功能
模块的使用方法:
- 使用模块就必须先导入模块
[from 模块名] import [模块 | 类 | 变量 | 函数 |*] [as 别名]
[中括号]:表示可选可不选
常用的组合:
- import 模块名
- from 模块名 import 类、变量、函数方法等
- from 模块名 import * ----- 表示导入这个模块的全部东西
- from 模块名 as 给模块起的别名
- from 模块名 import 功能名 as 给功能起的别名
导入模块
import 模块名
import 模块名
模块名. 方法名 (参数列表)
import time
print(time.localtime())
print(time.time())
print(time.gmtime())
print(time.ctime())
print(time.strftime("%Y-%m-%d %H:%M:%S",time.localtime()))
print(time.thread_time())
print(time.thread_time_ns())
print(time.perf_counter())
print(time.process_time())
print(time.process_time_ns())
time.struct_time(tm_year=2023, tm_mon=4, tm_mday=2, tm_hour=18, tm_min=47, tm_sec=37, tm_wday=6, tm_yday=92, tm_isdst=0)
1680432457.0442379
time.struct_time(tm_year=2023, tm_mon=4, tm_mday=2, tm_hour=10, tm_min=47, tm_sec=37, tm_wday=6, tm_yday=92, tm_isdst=0)
Sun Apr 2 18:47:37 2023
2023-04-02 18:47:37
0.046875
46875000
1024377.8040746
0.046875
46875000
from 模块名 import 方法名
使用方式:直接使用方法名
方法名 (形参列表)
from time import localtime,strftime,ctime
print(localtime())
print(strftime("%Y-%m-%d %H:%M:%S",localtime()))
print(ctime())
time.struct_time(tm_year=2023, tm_mon=4, tm_mday=2, tm_hour=19, tm_min=35, tm_sec=48, tm_wday=6, tm_yday=92, tm_isdst=0)
2023-04-02 19:35:48
Sun Apr 2 19:35:48 2023
from 模块名 import *
使用方式:直接使用方法名, 相当于把所有的方法都导入进来了
方法名 (形参列表)
from time import *
print(localtime())
print(strftime("%Y-%m-%d %H:%M:%S",localtime()))
print(ctime())
time.struct_time(tm_year=2023, tm_mon=4, tm_mday=2, tm_hour=19, tm_min=38, tm_sec=39, tm_wday=6, tm_yday=92, tm_isdst=0)
2023-04-02 19:38:39
Sun Apr 2 19:38:39 2023
as 定义别名
import 模块名 as 别名 [, 模块名 2 as 别名 2 , …] ------ 给模块名起别名
别名. 方法名 (实参列表) ------ 使用方式
from time import as t
print(t.localtime())
print(t.strftime("%Y-%m-%d %H:%M:%S",t.localtime()))
print(t.ctime())
from 模块名 import 方法名 as 别名 [, 方法名 2 as 别名 2 , 方法名 3 as 别名 3 …] ------ 给模块的方法起别名
别名 (实参列表) ------ 使用方式
from time import localtime as lt, strftime as st, ctime as ct
print(lt())
print(st("%Y-%m-%d %H:%M:%S", lt()))
print(ct())
time.struct_time(tm_year=2023, tm_mon=4, tm_mday=2, tm_hour=19, tm_min=46, tm_sec=47, tm_wday=6, tm_yday=92, tm_isdst=0)
2023-04-02 19:46:47
Sun Apr 2 19:46:47 2023
自定义模块
Python 中已经实现了很多模块,不过有时候会需要一些个性化模块,此时就可以通过自定义模块实现,也就是自己制作一个模块
新建一个 Python 的文件,命名为 my_modulel.py, 并在里面自定义函数
由此就完成了自定义模块
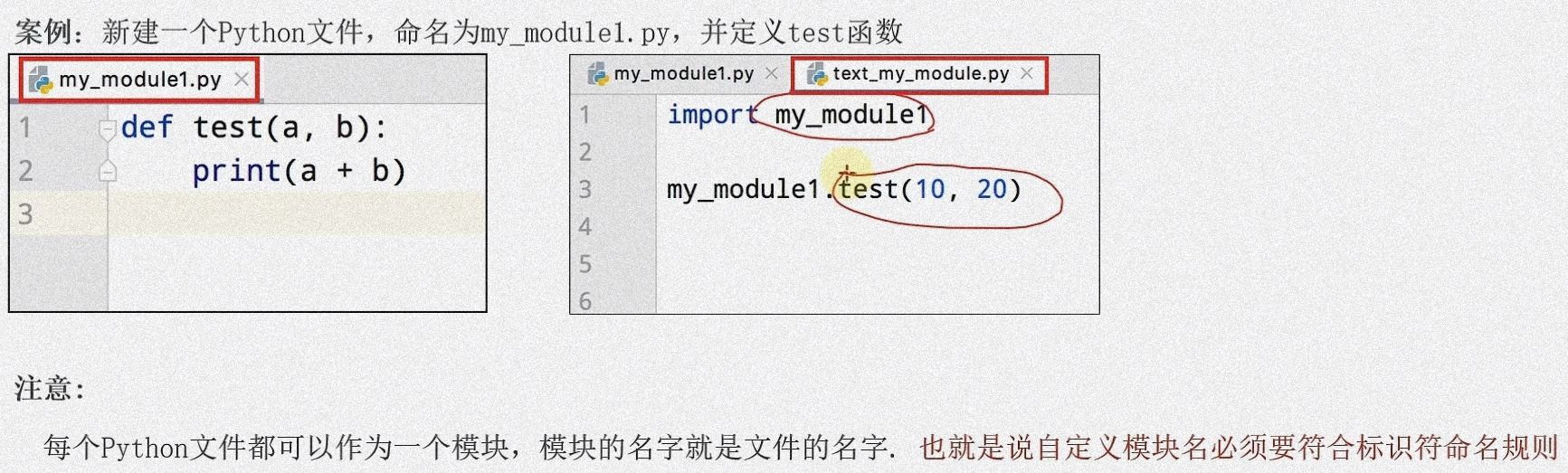
- 当导入多个模块的时候,且模块内有同名的方法,当调用该同名的方法时,会调用到导入位置靠后的那个模块的同名方法,即后面导入的模块会把前面导入的模块的方法给覆盖掉
__name__ == ‘__main__’
- __main__ 表示的是当前模块的对象,即当前文件名.py 的引用,它会随着当前要执行的窗口在哪而跟随
当哪个模块被直接执行时,该模块“name”的值就是“main”,当被导入另一模块时,“name”的值就是模块的真实名称。用一个类比来解释一下:记得小时候要轮流打算教室,轮到自己的时候(模块被直接执行的时候),我们会说今天是“我”(main)值日,称呼其他人时,我们就会直接喊他们的名字。所以,“main”就相当于当事人,或者说第一人称的“我”。
__name__ 则是代表的当前模块的包名, 每个模块的路径名都不同,如在 A.py 中,__name__ == A ,
在 B.py 中,__name__ 就等于 B,即代表当前的包名 __name__ == B
if __name__ == ‘__main__’
可以写代码,以用来测试
- 表示的是如果模块所在的路径名 == 当前所在的执行窗口路径名,则为真,那就可以自动执行该模块下的代码,否则就不自动执行该模块下的代码
print(__name__)
if __name__ == '__main__':
print("表示的是如果模块所在的路径名 = 当前所在的执行窗口路径名,则为真\n"
"那就可以自动执行该模块下的代码,否则就不自动执行该模块下的代码")
__main__
表示的是如果模块所在的路径名 = 当前所在的执行窗口路径名,则为真
那就可以自动执行该模块下的代码,否则就不自动执行该模块下的代码
#Package\B.py的代码如下
print(f"B模块的__name__ == {__name__}")
#在A.py模块下执行代码
from Package import B
print(f"A模块的__name__ == {__name__}")
B 模块的 __name__ == Package.B
A 模块的 __name__ == __main__
但是如果加了 if 后,它就不会自动执行 B 模块的 if __name__ == ‘__main__’ 下的代码了
#Package\B.py的代码如下
print("不在B模块下__name__ == '__main__'下的代码就会被自动执行")
if __name__ == "__main__": # if __name__ == "__main__" is True
print(f"B模块的__name__ == {__name__}")
#在A.py模块下执行代码
from Package import B
print(f"A模块的__name__ == {__name__}")
不在 B 模块下 _name_ == '__main__' 下的代码就会被自动执行
A 模块的 __name__ == __main__
__all__ 变量
如果一个模块文件中有 ==__all__== 变量,当使用 from 模块名 import * 时,只能导入这个变量列表里的元素,作用是控制 import * 的时候可以导入模块的功能
__all__ = [函数方法、变量、类等]

Python 包
自定义 Python 包
Python 包就是一个文件夹,在该文件夹下包含了一个 __init__.py 文件,该文件夹可用于包含多个模块文件,包的作用就是用于管理这些模块的存放的,如果文件夹没有 __init__.py,则它就不是 Python 包,而只是一个普通的文件夹而已,不具有导包作用
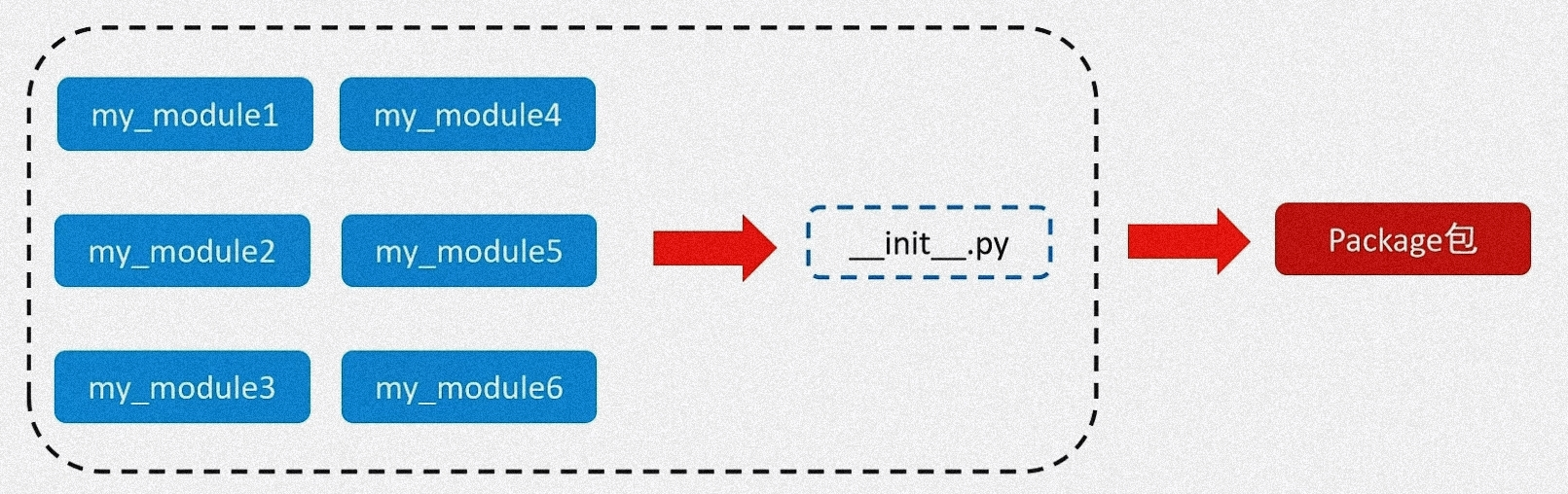
- 新建 Python 包
- 在新建的 Python 包下新建模块:自定义模块名.py
- 在自建的自定义模块名.py 下实现的方法、功能等
使用自定义包
from 自定义包名 import 自定义模块名
调用时
自定义模块名. 自定义功能名 (实参列表)
#Package\B.py的代码如下
def add(x, y):
return x + y
#在A.py模块下执行代码
from Package import B
print(B.add(1, 6))
7
直接导包的话
import Package.B
调用时
自定义包名. 自定义模块名. 自定义功能名 (实参列表)
#Package\B.py的代码如下
def add(x, y):
return x + y
#在A.py模块下执行代码
import Package.B
print(Package.B.add(4, 7))
11
方式 3:
在 Python 包文件夹下的 __init__.py 文件中添加 __all__ = [控制允许导入模块的元素]
from 自定义包名 import *
调用时:
自定义模块名. 自定义功能名 (实参列表)
安装第三方包
pip/pip3 install 包名称
卸载第三方包
pip uninstall 包名称
更新第三方包
pip install --upgrade 包名
下载国内的镜像第三方包
pip/pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称
面向对象
创建类
class 类名:
类的属性(成员变量)
类的方法(成员方法)
创建对象
基于类创建对象
class 类名:
类的实例化对象名 = 类名(构造器列表)
#简写理解
对象名 = 类名(构造器列表)
基于类创建属性
class 类名:
属性名 = 值
- 在 java 中,类里的属性可以直接先声明,不赋值,但是在 python 中类里的属性一定要赋值或者让其等于空值 (None)
基于类对象进行属性赋值
类的实例化对象名. 属性名 = 值
成员方法
类里面的函数的形参必须要带一个 self,且 python 中的 self 相当于 java 中的 this
class 类名:
属性名 = None
def 函数名(self, 形参名1, 形参名2 ,...):
self.属性名
方法体
- self – 用于表示类对象自身的意思
- 当使用类对象调用方法时,self 会自动被 python 传入
- 在方法内部,想要访问类里的属性,必须使用 self. 类属性名
调用成员方法
第一种:直接调用
类名. 方法名 ()
第二种:先创建实例化对象再调用
对象名 = 类名 ()
对象名. 方法名 ()
访问类的属性
第一种:直接访问
类名. 属性名
第二种:先创建实例化对象再访问
对象名 = 类名 ()
对象名. 属性名
构造方法 (构造器)
- python 的构造方法在创建类对象的时候会自动执行
- python 的构造方法在创建对象的时候,将传入的参数自动传递给
__init__(self)方法使用
class 类名:
属性名 = None
name = None #可以删除
def __init__(self, name, 形参名, ...):
self.name = name #因为__init__里面有name了,类里的属性name可以省略
python 的构造方法相当于 java 的构造器
调用构造器时
对象名 = 类名 (实参列表)
类的内置方法 (魔术方法)
魔术方法都是类似于 __方法名__(参数列表) 这样的形式
__str__ 为 toString 方法
python 中的 __str__(self,...) 方法跟 java 中的 toString 方法一样,都是自定义输出类的字符串内容
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f"{self.name}已经{self.age}岁了"
print(Student("小明", 18))
小明已经 18 岁了
__lt__ 小于符号的比较
重写 __lt__(self,other)方法可以比较两个对象的属性的大小,返回值为 True 或 False
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __lt__(self, other):
return self.age < other.age
print(Student("小明", 18) < Student("小黄",20))
True
__le__ 小于等于的对象比较
重写 __le__(self,other)方法可以比较两个对象的属性的大小,该方法可用 <=、>= 或 == 者三种符号,返回值为 True 或 False
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __le__(self, other):
return self.age <= other.age # 如果self.age <= other.age 即为 True
print(Student("小明", 18) >= Student("小黄", 20))
False
__eq__ 判断属性相等
一般重写 __eq__(self,other)方法可以比较两个对象的属性是否相等,如果相等返回 True,不相等则返回 False
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __eq__(self, other):
return self.age == other.age # 如果self.age <= other.age 即为 True
print(Student("小明", 18) == Student("小黄", 20))
False
私有成员
创建私有成员属性
__属性名 = 值
- 私有成员变量:变量名以
__开头 (2 个下划线)
创建私有成员方法
def __方法名(self, 形参名, ...):
方法体
- 私有成员方法:方法名以
__开头 (2 个下划线)
类的外部无法访问私有属性或调用私有方法
继承
python 中的继承语法
class 子类名(父类名):
子类类体
- 子类拥有父类的所有属性和方法 (私有的除外)
多个子类继承一个父类
python 和 java 一样允许多子类继承一个父类

class Animal:
def eat(self):
print("Animal的eat()方法")
class Dog(Animal):
def eat(self):
print("Dog重写父类的eat()方法")
class Cat(Animal):
def eat(self):
print("Cat重写父类的eat()方法")
class Pig(Animal):
def eat(self):
print("Pig重写父类的eat()方法")
self = None
python 中的方法的形参 self 若没有赋值,有时会报错,此时需要使用具名实参的方法让 self 不赋值时有空值
class Animal:
def eat(self):
print("Animal的eat()方法")
class Dog(Animal):
def eat(self):
print("Dog重写父类的eat()方法")
class Cat(Animal):
def eat(self):
print("Cat重写父类的eat()方法")
class Pig(Animal):
def eat(self):
print("Pig重写父类的eat()方法")
Pig.eat(self=None) #必须让self = None,否则会报错
Pig 重写父类的 eat() 方法
一个子类继承多个父类
但是 python 与 java 不同的是,python 还允许一个子类继承多个父类
class 子类名(父类1, 父类2, 父类3, ...):
子类类体
- 该子类继承所有父类的属性和方法 (私有的除外)
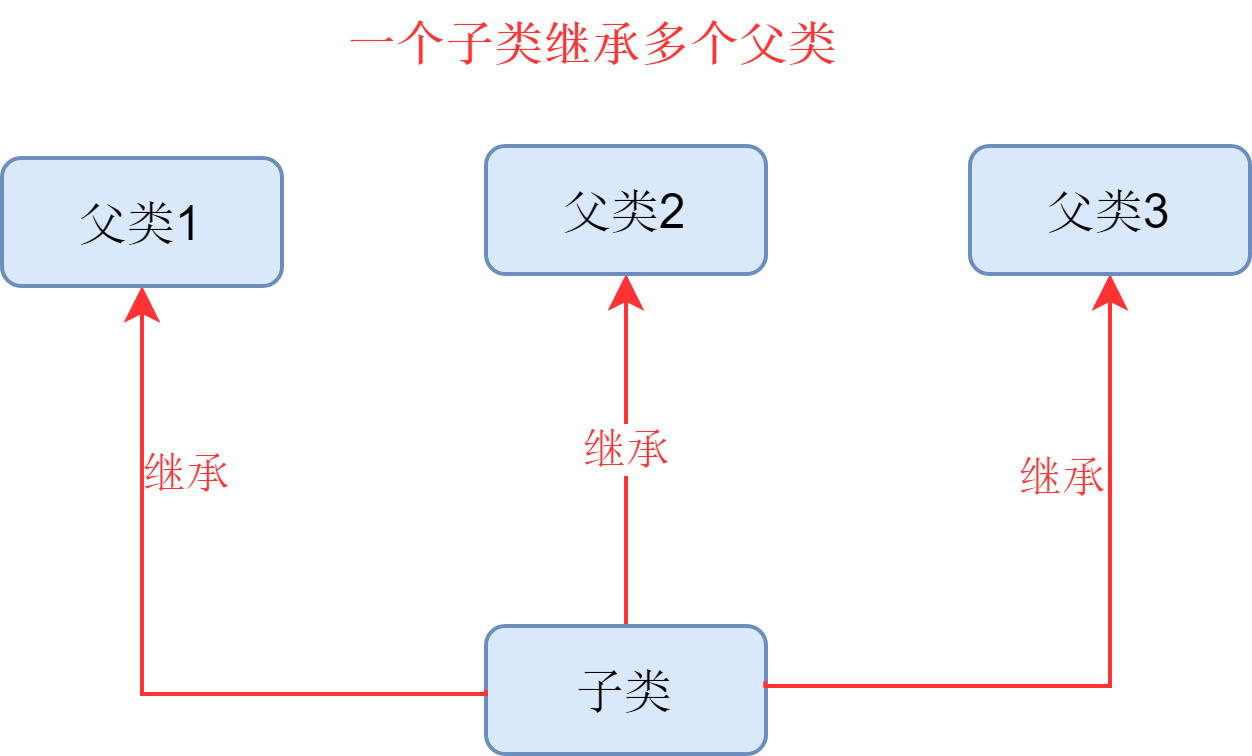
重写方法 / 属性
python 重写父类的方法没有注解,不会有提示,python 中还可以重写父类属性
class Animal:
name = None
def eat(self):
print(f"Animal类的eat()方法,动物名字为{self.name}")
class Cat(Animal):
name = "小黄猫"
def eat(self):
print(f"Cat类的eat()方法,小猫的名字为{self.name}")
Animal().eat()
Cat().eat()
Animal 类的 eat() 方法, 动物名字为 None
Cat 类的 eat() 方法,小猫的名字为小黄猫
子类如果没有重写父类的方法,当调用时,调用的是父类的方法
class Animal:
name = None
def eat(self):
print(f"Animal类的eat()方法,动物名字为{self.name}")
class Cat(Animal):
name = "小黄猫"
def __init__(self):
self.eat()
Cat()
Animal 类的 eat() 方法, 动物名字为小黄猫
当子类重写父类的方法后,调用的就是子类自己的重写方法了
class Animal:
name = None
def eat(self):
print(f"Animal类的eat()方法,动物名字为{self.name}")
class Cat(Animal):
name = "小黄猫"
def __init__(self):
self.eat()
def eat(self):
print(f"Cat类的eat()方法,小猫的名字为{self.name}")
Cat()
Cat 类的 eat() 方法,小猫的名字为小黄猫
调用父类成员
方式 1:
父类名. 父类属性名
父类名. 成员方法 (self)
super() 访问父类
方式 2:在子类中使用 super()
super(). 父类成员变量
super(). 父类成员方法 ()
class Animal:
name = None
def eat(self):
print(f"Animal类的eat()方法,动物名字为{self.name}")
class Cat(Animal):
name = "小黄猫"
def eat(self):
print(f"Cat类的eat()方法,小猫的名字为{self.name}")
def __init__(self):
# 调用父类的属性的两种方法
print(f"父类名.属性名:{Animal.name}")
print(f"super().父类属性名:{super().name}")
print()
# 调用父类的两种方法
print("父类名.方法名(self):")
Animal.eat(self)
print(f"super().父类方法名():")
super().eat()
Cat() #创建匿名类
父类名. 属性名:None
super(). 父类属性名:None父类名. 方法名 (self):
Animal 类的 eat() 方法, 动物名字为小黄猫
super(). 父类方法名 ():
Animal 类的 eat() 方法, 动物名字为小黄猫
类型注解
类型注解可以帮助第三方 IDE 工具 (如 Pycharm) 对代码进行类型推断,协助做代码提示,主要用于让开发者对变量进行数据类型的注释
- 支持变量的类型注解
- 支持函数 (方法) 形参列表和返回值的类型注解
变量的类型注解
变量名 : 数据类型注解 = 值
int_var: int = 10 # 标记为该变量的数据类型为int型
float_var: float = 20.5 # 标记为该变量的数据类型为float型
bool_var: bool = True # 标记为该变量的数据类型为bool型
str_var: str = "字符串类型注解" # 标记为该变量的数据类型为str型
类对象的类型注解
对象名 : 类名的注解 = 类名 ()
class Student:
pass
#标记stu1为Student类的对象
stu1: Student = Student()
数据容器的类型注解
容器名: 数据容器类型的注解
容器名: 数据容器类型的注解 = 数据容器
my_list: list = [1, 2, 3]
my_tuple: tuple = (1, 2, 3)
my_set: set = {1, 2, 3}
my_dict: dict = {"name": "刘伟"}
my_str: str = "你好,世界"
容器类型详细注解
数据容器名: 容器类型 [容器里元素的类型]
my_list: list[int] = [1, 2, 3]
my_tuple: tuple[list[int, str, bool], int, tuple[int, int, int]] = ([1, "str", True], 4, (5, 6, 7))
my_set: set[int, str, bool] = {1, "str", True}
my_dict: dict[str, int] = {"money": 666}
-
元组类型设置类型详细注解,需要将每一个元素的数据类型都标记出来
-
字典类型设置类型详细注解,需要 2 个类型注解,第一个是 key 数据类型的注解,第二个是 value 数据类型的注解
注释中的类型注解
#type : 数据类型的注解
import random
class Cat:
pass
int_var = random.randint(1, 10) # type:int
list_var = [1, 2, 3] # type:list
cat_var = Cat() # type:Cat
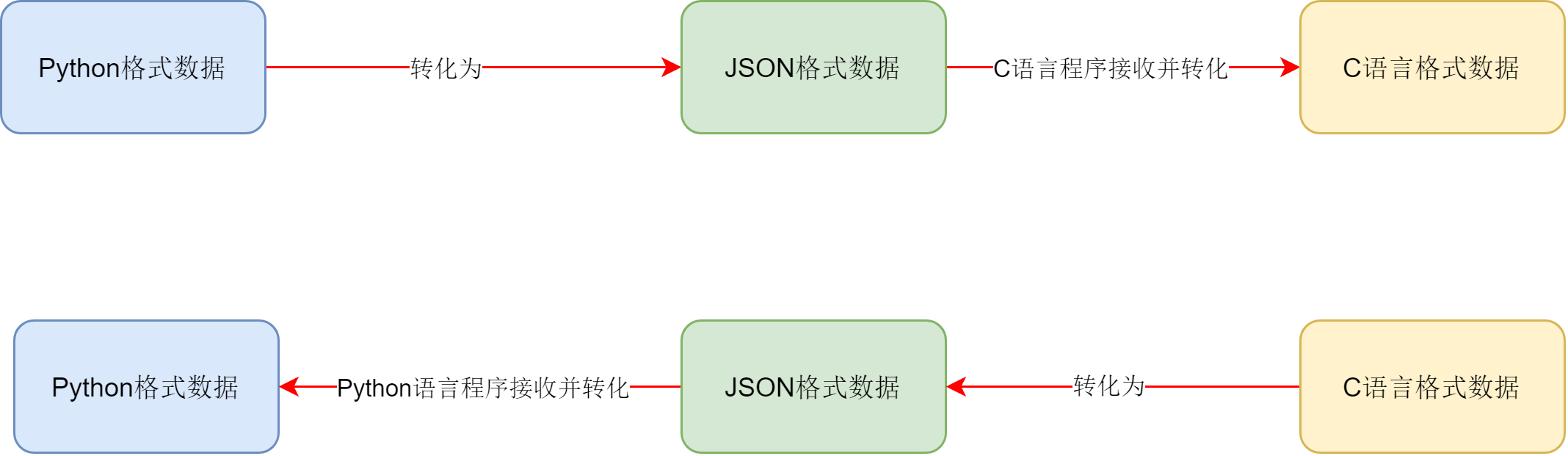
JSON 数据格式的转换
什么是 JSON?
- JSON 是一种轻量级的数据交互格式。可以按照 JSON 指定的格式去组织和封装数据,JSON 本质上是一个带有特定格式的字符串
主要功能:
- JSON 是一种在各个编程语言中流通的数据格式,负责不同编程语言中的数据传递和交互
JSON 的数据格式:
第一种:相当于python中的字典
JSON = {标记名1:值1, 标记名2:值2, .
..}
第二种:相当于在python中列表嵌套字典
[ {标记名1:值1, 标记名2:值2, ...}, {标记名1:值1, 标记名2:值2, ....}, ... ]
-
python 数据与 json 数据的转化
导入 json 模块
import json
-
准备符合格式 json 格式要求的 python 数据
python_data = [{“name”: “老王”, “age”: 20}, {“name”: “张三”, “age”: 20}]
-
通过 ``json.dumps(python_data)` 方法把 python 数据转化为 json 数据
json_data = json.dumps(python_data)
-
通过
json.loads(json_data)方法把 json 数转化为 python 数据python_data = json.loads(json_data)
# 导入json模块
import json
python_data = [{"name": "老王", "age": 20}, {"name": "张三", "age": 20}]
# 将python数据转化为json数据
json_data = json.dumps(python_data)
print(f"json_data的数据格式为:{json_data}")
print(f"让json_data的数据显示正常{json.dumps(python_data,ensure_ascii=False)}")
print(f"json_data的数据类型为:{type(json_data)}")
# 将json数据转化为python数据
python_data = json.loads(json_data)
print(f"python_data的数据类型为:{python_data}")
print(f"python_data的数据类型为:{type(python_data)}")
json_data 的数据格式为:[{“name”: “\u8001\u738b”, “age”: 20}, {“name”: “\u5f20\u4e09”, “age”: 20}]
json_data 的数据类型为:[{‘name’: ‘老王’, ‘age’: 20}, {‘name’: ‘张三’, ‘age’: 20}]
json_data 的数据类型为:<class ‘str’>
python_data 的数据类型为:[{‘name’: ‘老王’, ‘age’: 20}, {‘name’: ‘张三’, ‘age’: 20}]
python_data 的数据类型为:<class ‘list’>
iodraw 导出图不清晰的问题
直接在缩放里面缩放倍数,上图是缩放了 300% 的图,必以前清晰了不少
解决 draw.io(diagrams.net)导出图片文件时出现模糊(锯齿状)问题 _diagrams 导出的图如何提高分辨率 _ 仰望青空的博客 -CSDN 博客
pyecharts 模块
Echarts 是个由百度开源的数据可视化,该模块可用于做数据可视化效果图
官网教程链接:pyecharts - 一个用爱构建的 Python Echarts 绘图库。
pyecharts 的画廊:Document (pyecharts.org)
基础折线图
-
导入 Line 类
from pyecharts.charts import Line
建议这样导入:
from pyecharts.charts import *
from pyecharts.options import *
-
得到折线图的对象
折线图对象名 = Line()
-
添加 x 轴数据
折线图对象名.add_xaxis([x 轴的列表的数据])
-
添加 y 轴数据
折线图对象名.add_yaxis(“标题名”,[y 轴的列表数据])
-
生成图表
折线图对象名.render()
全局配置
全局配置选项可以通过以下方法设置
先获取图表的具体对象
图表对象名.set_global_opts(
#标题的设置
title_opts = TitleOpts("标题名",pos_left = "center", pos_bottom = "1%"),
#图例的配置
legend_opts = LegendOpts(is_show = True),
#工具箱的配置
toolbox_opts = ToolboxOpts(is_shwo = True),
#可视化地图设置
visualmap_opts = VisualMapOpts(is_shwo = True)
)
记得导入对应的包
from pyecharts.options import TitleOpts,LegendOpts…
工具箱配置很好用,建议配置
数据处理
JSON 格式化 / 解析网站:懒人工具 -json 在线解析 - 在线 JSON 格式化工具 -json 校验 - 程序员必备 (ab173.com)
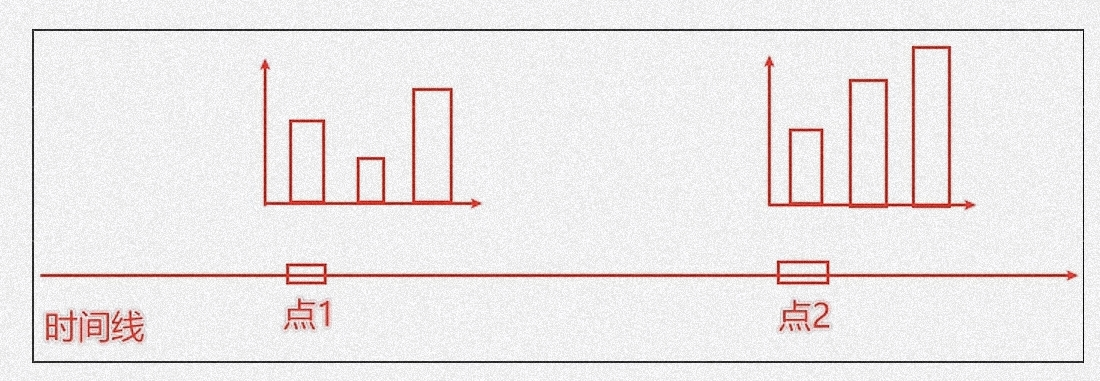
基础时间线柱状图
**Timeline() -- 时间线**
假设一个 Bar、Line 对象是一张张图表,时间线就是创建一个一维的 x 轴,轴上的每一个点就是一个图表对象
绘制方法
-
导入时间线的类
from pyecharts.charts import Timeline,Bar
from pyecharts.options import *
-
创建第一柱状图对象并配置数据
bar1 = Bar() bar1.add_xaxis(["中国","美国","英国"]) bar1.add_yaxis("GDP",[30,20,10],label_opts=LabelOpts(position="right")) #反转x,y轴的数据 bar1.reversal_axis() -
创建第二个柱状图并配置数据
bar2 = Bar() bar2.add_xaxis(["中国","美国","英国"]) bar2.add_yaxis("GDP",[50,30,15],label_opts=LabelOpts(position="right")) #反转x,y轴的数据 bar2.reversal_axis() -
创建时间线对象
时间线对象名 = Timeline() -
将每一个 bar 柱状图对象都添加到时间线对象中,且给每一个 bar 柱状图对象分配时间
时间线对象名 = Timeline() 时间线对象名.add(bar1, "2021年7月GDP") 时间线对象名.add(bar2, "2021年8月GDP") -
通过时间线对象绘图,并起名
时间线对象名.render("基础柱状图-时间线.html")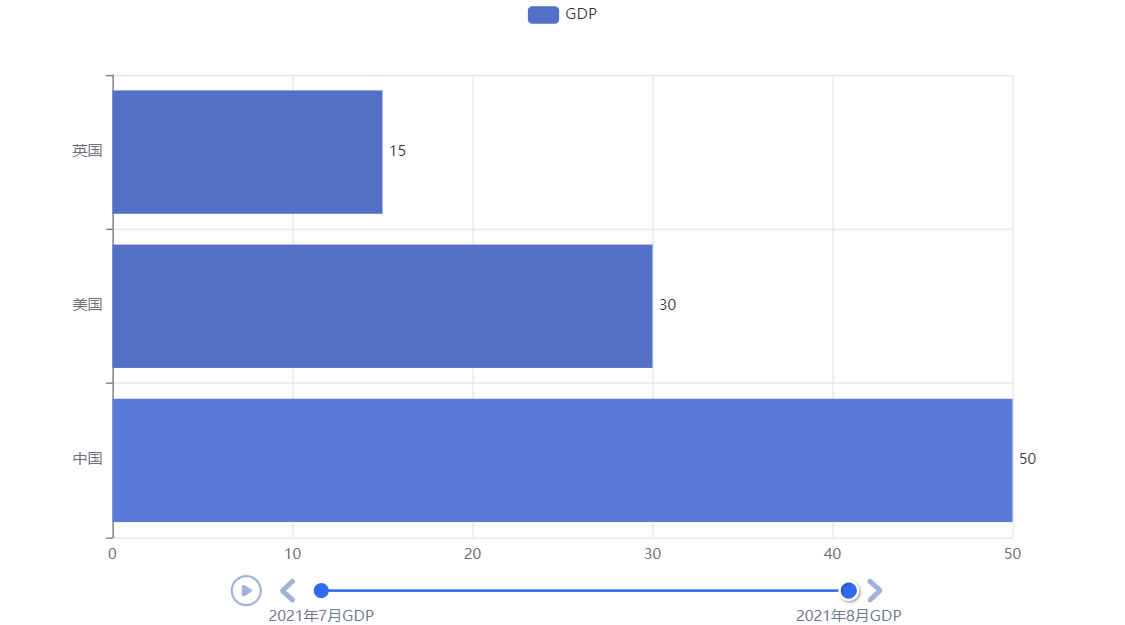
-
自动播放设置
时间线对象名.add_schema( play_interval = 1000, #设置播放的时间间隔,单位毫秒 is_时间线对象名_show = True, #是否在自动播放的时候,显示时间线 is_auto_play = True, #是否自动播放 is_loop_play = True #是否自动循环播放 )
操作 MySQL
安装第三方库 pymysql
在命令行输入以下指令进行安装
pip3 install PyMySQL
导入 Connection 类
from pymysql import Connection
#获取 MySQL 数据库的链接对象
connecion = Connection(
host = ‘主机名 (或 IP 地址)’ , – 默认为 localhost
port = 端口 , 默认 3306
user = ‘账户名’ , – 默认为 root
password = ‘密码’
)
关闭数据库的链接
链接对象.close()
select 选择连接数据库
链接对象.select_db(“数据库名”) ---- mysql 中是:use 数据库名称
cursor 获取光标对象
光标对象名 = 链接对象.cursor()
- 指获取连接数据建库后计算机的光标对象,然后通过光标去操作数据库
execute 使用光标执行 sql 语句
光标对象名.execute(“sql 语句”)
from pymysql import Connection #导入链接类
#创建链接对象
connect = Connection(
host='localhost',
port=3306,
user='root',
password='22498946'
)
connect.select_db("world") #选择数据库
cursor = connect.cursor() #创建光标对象
#通过光标对象.execute 执行sql语句
cursor.execute("create table connectMysql(id int,name varchar(6),age int ,gender varchar(2));")
#关闭数据库连接
connect.close()
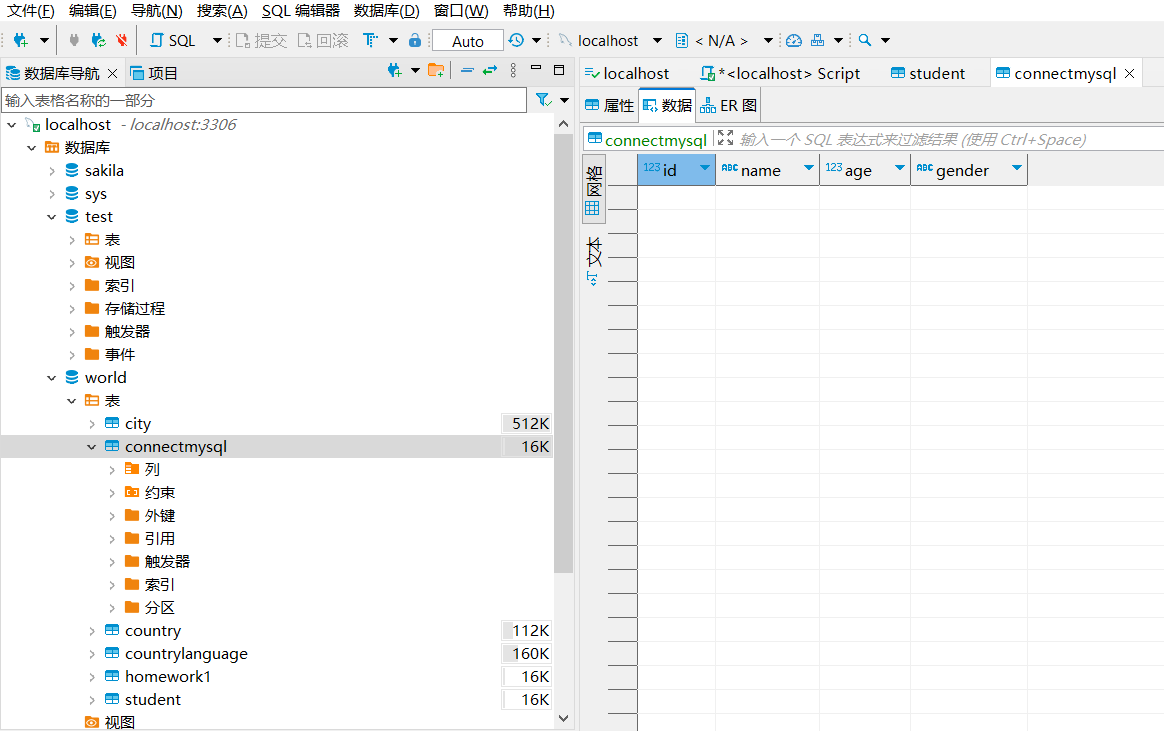
fetchall 获取查询的结果
光标对象名.execute(“select * from 数据库名”)
结果对象名 : tuple = 光标对象.fetchall()
for element in 结果对象名:
print(element)
from pymysql import Connection #导入链接类
#创建链接对象
connect = Connection(
host='localhost',
port=3306,
user='root',
password='22498946'
)
connect.select_db("world") #选择数据库
cursor = connect.cursor() #创建光标对象
# #通过光标对象.execute 执行sql数据查询语句
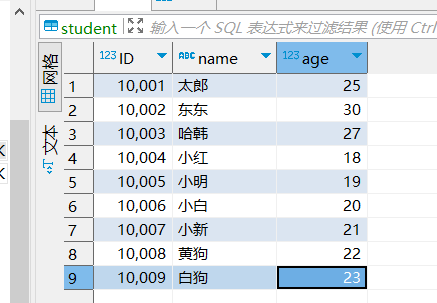
cursor.execute("select * from student") #转到当前student页面
results = cursor.fetchall()
for element in results:
print(element)
#关闭数据库连接
connect.close()
(10001, ‘太郎’, 25)
(10002, ‘东东’, 30)
(10003, ‘哈韩’, 27)
(10004, ‘小红’, 18)
(10005, ‘小明’, 19)
(10006, ‘小白’, 20)
(10007, ‘小新’, 21)
(10008, ‘黄狗’, 22)
(10009, ‘白狗’, 23)
commit 确认数据更改到表
pymysql 在执行数据插入时或其他产生数据更改的 SQL 语句时,默认是需要提交更改的,即,需要通过代码“确认”这种更改行为
确认更改行为
链接对象.commit()
from pymysql import Connection #导入链接类
#创建链接对象
connect = Connection(
host='localhost',
port=3306,
user='root',
password='22498946'
)
connect.select_db("world") #选择数据库
cursor = connect.cursor() #创建光标对象
#通过光标对象.execute 执行sql语句
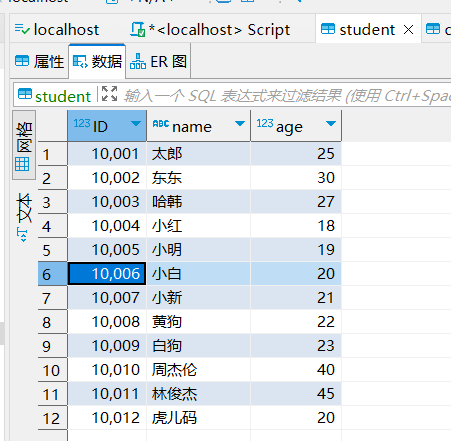
cursor.execute("insert into student values (10010,'周杰伦',40),(10011,'林俊杰',45),(10012,'虎儿码',20);")
#确认数据更改的操作 ------------- 重点
connect.commit()
#查询表数据
cursor.execute("select * from student")
results = cursor.fetchall()
for element in results:
print(element)
#关闭数据库连接
connect.close()
(10001, ‘太郎’, 25)
(10002, ‘东东’, 30)
(10003, ‘哈韩’, 27)
(10004, ‘小红’, 18)
(10005, ‘小明’, 19)
(10006, ‘小白’, 20)
(10007, ‘小新’, 21)
(10008, ‘黄狗’, 22)
(10009, ‘白狗’, 23)
(10010, ‘周杰伦’, 40)
(10011, ‘林俊杰’, 45)
(10012, ‘虎儿码’, 20)
自动确认提交数据更改
链接对象名 = Connection(
autocommit = True #设置自动确认提交数据更改的操作,设置后无需手动提交
)
from pymysql import Connection # 导入链接类
# 创建链接对象
connect = Connection(
host='localhost',
port=3306,
user='root',
password='22498946',
autocommit=True #设置自动确认提交数据更改到表
)
connect.select_db("world") # 选择数据库
cursor = connect.cursor() # 创建光标对象
# 通过光标对象.execute 执行sql语句
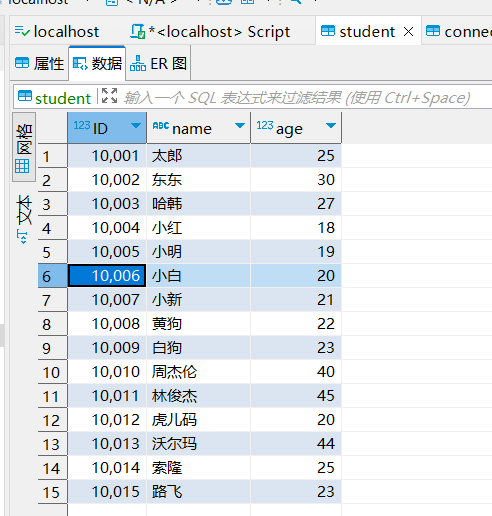
cursor.execute("insert into student values (10013,'沃尔玛',44),(10014,'索隆',25),(10015,'路飞',23);")
# 无需使用commit提交
# 关闭数据库连接
connect.close()
综合数据分析
将 D 盘下的 2011 年 1 月销售数据.txt 文件的 1009 条销售记录存入数据库中
# _*_coding:utf-8_*_
# CYX_Python 编写
from pymysql import Connection
class Record:
def __int__(self, date, order_ID, sales, province):
self.date = date
self.order_ID = order_ID
self.sales = sales
self.province = province
record_order = [] # 创建空列表
with open("D:\\2011年1月销售数据.txt", "r", encoding="utf-8") as file:
orders = file.readlines() # 将每一行数据作为一个元素存到orders列表中
for element in orders:
record = Record() # 在这里刷新创建对象
records = element.split(",",) # 把每条记录的日期,订单id,销售额,省份都拆开
record.date = records[0] # 再分别记录到每一个对象的对象属性里去
record.order_ID = records[1]
record.sales = records[2]
record.province = records[3]
record_order.append(record) # 最后将每个订单记录的对象存入列表中
# 连接数据库
database_connect = Connection(
host="localhost",
port=3306,
user='root',
password='22498946',
autocommit=True
)
cursor = database_connect.cursor() # 获取光标
cursor.execute("create database order_sales charset utf8") # 创建销售单的数据库
database_connect.select_db("order_sales") # 连接创建的该数据库
#创建销售记录表
cursor.execute(
"create table sales_record(data varchar(255),order_ID varchar(255),sales varchar(255),province varchar(255))")
#这一步一定要注意写入sql语句时,格式为varchar的字符串一定要用单引号括起来,python的对象数据是字符串,使用sql语句时,依然要用单引号将{}对象包围起来,即'{对象数据}'
for i in range(len(record_order)):
cursor.execute(
f"insert into sales_record values ('{record_order[i].date}','{record_order[i].order_ID}','{record_order[i].sales}','{record_order[i].province}');")
# 关闭数据库
database_connect.close()
PySpark 库
该库的使用需要配置 java 环境,JDK8 以上的都行
Apache Spark 是用于大规模数据 (large-scala data) 处理的统一 (unified) 分析引擎
简单来说,Spark 是一款分布式的计算框架,用于调度成百上千的服务器集群,计算 TB、PB、乃至 EB 级别的海量数据

Spark 对 Python 语言的支持,重点体现在 Python 的第三方库上 PySpark 上,它是 Spark 官方开发 Python 的第三方库
PySpark 库的安装
在命令行中执行以下命令进行 PySpark 库的安装
pip install pyspark
或使用国内代理镜像网站 (清华大学源)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
PySpark 执行环境入口对象的构建
想要使用 PySpark 库完成数据处理,首先需要构建一个执行环境入口的对象
PySpark 的执行环境入口的对象是:类 SparkContext 的类对象
导包
from pyspark import SparkConf ,SparkContext
创建 SparkConf 类对象
SparkConf 类对象名 = SparkConf().setMaster(“local[*]”).\setAppName(“启动名”)
- 注意 SparkConf(), 这里还有个小括号别忘了,老是忘记括号了
基于 SparkConf 类对象创建 SparkContext 类对象
SparkContext 类对象名 = SparkContext(conf = SparkConf 类对象名) ----- 入口对象:SparkContext 类对象名
停止 Spark 程序
SparkContext 类对象名.stop()
PySpark 的编程模型
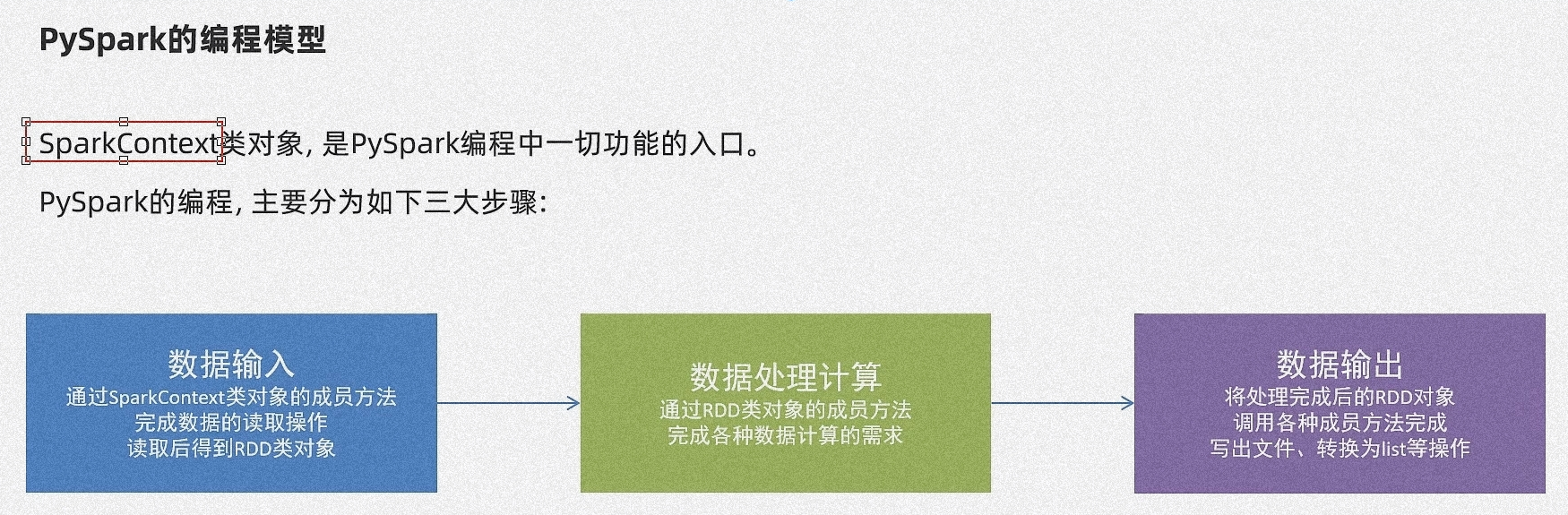
处理过程:
数据输入:通过 SparkContext 完成对数据读取
数据计算:读取到的数据转换为 RDD 对象,调用 RDD 的成员方法进行迭代计算
数据输出:调用 RDD 的数据输出相关的成员方法,将结果输出到 list、元组、字典、文本文件、数据库等
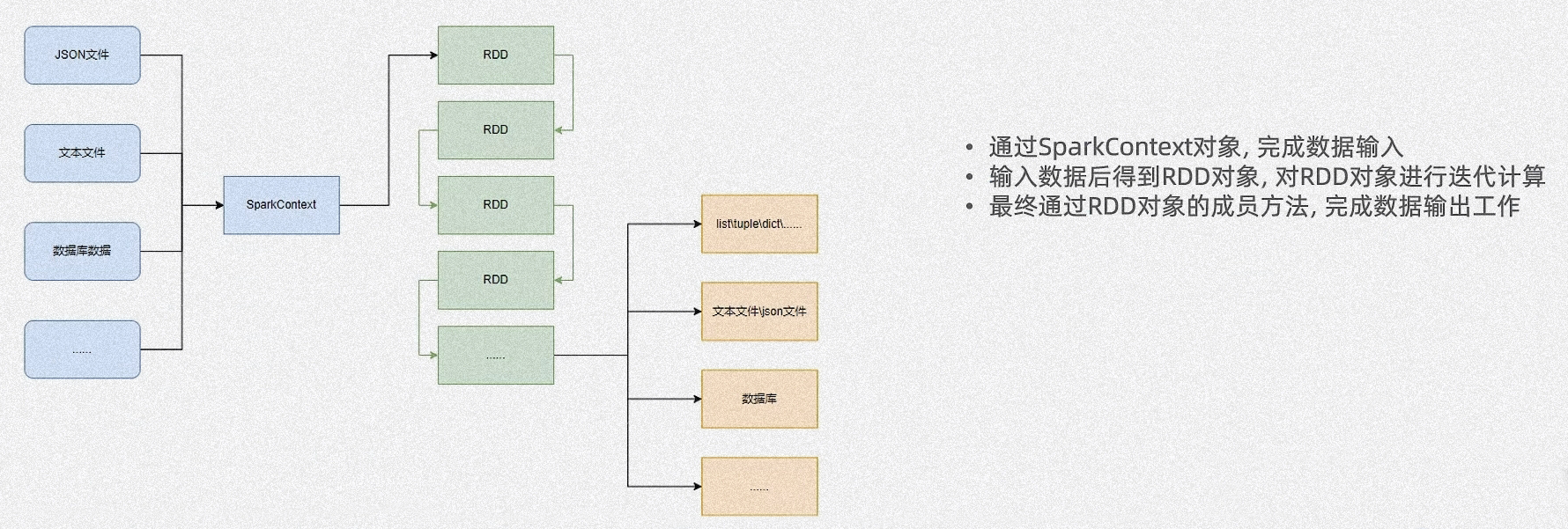
数据输入
RDD 对象
PySpark 支持多种数据的输入,在输入完成后,都会得到一个 RDD 类对象
RDD 全称为:弹性分布式数据集(Resilient Distributed Dataset)
PySpark 对数据的处理,都是以 RDD 对象为载体,即
- 数据存储在 RDD 内
- 各类数据的计算方法,也都是 RDD 的成员方法
- RDD 的数据计算方法,返回值依旧是 RDD 对象
parallelize 数据容器转 RDD 对象
PySpark 支持通过 SparkContext 对象的 parallelize 成员方法,将 list、tuple、set、dict、str 转换为 PySpark 的 RDD 对象
转 RDD 对象方法 parallelize
RDD 对象名 = SparkContext 类对象名.parallelize(数据容器的对象)
- 字符串会被拆分成一个个字符,存入 RDD 对象
- 字典仅有 key 会被存入 RDD 对象
collect 输出 RDD 对象的内容
RDD 对象名.collect()
# 创建载入执行环境的入口
from pyspark import SparkConf, SparkContext
# 注意SparkConf(),这里还有个小括号别忘了,老是忘记括号了
spark_conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
spark_context = SparkContext(conf=spark_conf)
# 将数据容器加载到RDD对象中
RDD1 = spark_context.parallelize([1, 2, 3, 4, 5]) # 将列表list加载到RDD对象中
RDD2 = spark_context.parallelize((1, 2, 3, 4, 5)) # 将元组tuple加载到RDD对象中
RDD3 = spark_context.parallelize({1, 2, 3, 4, 5}) # 将集合set加载到RDD对象中
RDD4 = spark_context.parallelize("abcdefg") # 将字符串str加载到RDD对象中
RDD5 = spark_context.parallelize({"key1": "value1", "key2": "value2"}) # 将字典dict加载到RDD对象中
# 输出RDD对象的内容
print(RDD1.collect())
print(RDD2.collect())
print(RDD3.collect())
print(RDD4.collect()) #注意字符串被拆分了
print(RDD5.collect()) #注意只存入了字典的key
# 停止spark程序
spark_context.stop()
[1, 2, 3, 4, 5]
[1, 2, 3, 4, 5]
[1, 2, 3, 4, 5]
[‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’, ‘g’]
[‘key1’, ‘key2’]
textFile 读取文件转换为 RDD 对象
SparkContext 类对象名.textFile(“文件路径”)
from pyspark import SparkConf, SparkContext
# 注意SparkConf(),这里还有个小括号别忘了,老是忘记括号了
spark_conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
spark_context = SparkContext(conf= spark_conf)
#textFile方法读取文件路径
RDD = spark_context.textFile("D:\\f1.txt")
print(RDD.collect())
# 停止spark程序
spark_context.stop()
[‘当我和世界不一样’, ‘那就让我不一样’, ‘坚持对我来说’, ‘就是以刚克刚’, ‘我如果对自己妥协’, ‘如果对自己说谎’, ‘即使别人原谅’, ‘我也不能原谅’, ‘最美的愿望 一定最疯狂’, ‘我就是我自己的神’, ‘在我活的地方’, ‘我和我最后的倔强’]
map 方法
map 成员方法又可以叫 map 算子
RDD 对象名.map(f:(T) -> U)
- map 成员方法,是将 RDD 里面的每个元素一条条处理 (基于 map 方法中接收的函数按照其定义的函数逻辑处理) 返回新的 RDD 对象
- f:表示这是一个函数 (方法)
- (T) -> U :表示这是方法的定义
- ()表示传入参数 (T) 表示传入 1 个参数 (U) 表示没有传入参数
- T 是泛型的代称,在这里表示 任意类型
- U 也是泛型的代称,在这里表示 任意类型
- -> U :表示返回值
- (T) -> U :表示这是一个方法,该方法接收一个参数传入,传入的参数类型不限,运算后得到一个类型不限的返回值
- (A) -> A :表示这是一个方法,该方法接收一个参数传入,传入的参数类型不限,运算后得到一个和传入参数类型一致的返回值
将的那么麻烦,实际上是
---------- 配置环境 ------------
import os
os.environ[‘PYSPARK_PYTHON’] = “python.exe 解释器的路径”---------- 防止报错 ------------
RDD 对象名.map(定义函数名)
-
注意只需要传入函数名就行了,千万不要写个括号,如函数名 () 这是错的,只需要写入函数名就行了
-
将 RDD 里面的每个元素都传给 map 里面定义的函数 [该函数必须有 1 个形参],按照该函数定义的逻辑处理 RDD 里面的每个元素,然后将其每个元素的运算结果返回,得到一个新的 RDD 对象
# 创建载入执行环境的入口
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/Python/python.exe"
# 注意SparkConf(),这里还有个小括号别忘了,老是忘记括号了
spark_conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
spark_context = SparkContext(conf=spark_conf)
# 将数据容器加载到RDD对象中
RDD1 = spark_context.parallelize([1, 2, 3, 4, 5]) # 将列表list加载到RDD对象中
#自己定义函数,且必须要有一个形参,里面的函数体的方法自己写
#可以使用lambda函数写进行优化
def rdd_add(data):
return data + 5
#又反了个错误,这里就要注意传入的函数不需要()括号了,一定要去掉括号!!!只需要传入函数名就行了
print(f"新的RDD1里面的元素为:{new_RDD1.collect()}")#将RDD1的每个元素传入函数处理后返回得到一个新的RDD
print(new_RDD1.collect())
#停止spark程序
spark_context.stop()
新的 RDD1 里面的元素为:[6, 7, 8, 9, 10]
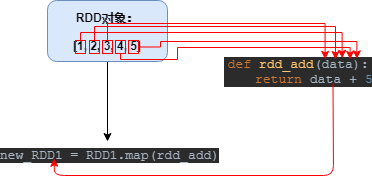
匿名 lambda 函数写法
优化写法,直接写匿名 lambda 函数就行了,省事
new_RDD1 = RDD1.map(lambda data: data * 10)
新的 RDD1 里面的元素为:[10, 20, 30, 40, 50]
链式调用
- 指对于同一类型的对象,可以无限调用返回自己本身的方法 (通过该对象调用方法,返回的仍然是同一类型的对象)
即对于返回值是新的 RDD 的成员方法,可以通过链式调用的方法多次调用该方法或其他成员方法
RDD 对象名.map(函数名 1).map(函数名 2).map(函数名 3)…
map 方法的链接调用,因为返回的都是 RDD 对象,所以可以一直链式调用
# 创建载入执行环境的入口
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/Python/python.exe"
# 注意SparkConf(),这里还有个小括号别忘了,老是忘记括号了
spark_conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
spark_context = SparkContext(conf=spark_conf)
# 将数据容器加载到RDD对象中
RDD1 = spark_context.parallelize([1, 2, 3, 4, 5]) # 将列表list加载到RDD对象中
#链式调用!!!!!!!!!!!!!!!!!!!!!
new_RDD1 = RDD1.map(lambda data: data * 10).map(lambda data: data * 2).map(lambda data: data + 5)
print(f"新的RDD1里面的元素为:{new_RDD1.collect()}")
# 停止spark程序
spark_context.stop()
新的 RDD1 里面的元素为:[25, 45, 65, 85, 105]
flatMap 方法
RDD 对象名.flatMap()
- 对 rdd 对象执行 flatMap 操作,该方法跟 map 方法基本一致,只不过如果遇到了 rdd 的嵌套会对 rdd 自动进行解除嵌套的操作,也就是说就比 map 方法多个解除嵌套的功能而已
# 创建载入执行环境的入口
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/Python/python.exe"
# 注意SparkConf(),这里还有个小括号别忘了,老是忘记括号了
spark_conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
spark_context = SparkContext(conf=spark_conf)
# 将数据容器加载到RDD对象中
rdd = spark_context.parallelize(["我 要 通 过", "使 用 flatMap 方 法", "解 除 嵌 套"])
new_rdd1 = rdd.map(lambda rdd:rdd.split(" "))
new_rdd2 = rdd.flatMap(lambda rdd:rdd.split(" "))
print(f"使用map方对rdd里面的元素进行分割后,rdd变为:{new_rdd1.collect()}")
print(f"使用flatmap方对rdd里面的元素进行分割后,rdd变为:{new_rdd2.collect()}")
使用 map 方对 rdd 里面的元素进行分割后,rdd 变为:[[‘我’, ‘要’, ‘通’, ‘过’], [‘使’, ‘用’, ‘flatMap’, ‘方’, ‘法’], [‘解’, ‘除’, ‘嵌’, ‘套’]]
使用 flatmap 方对 rdd 里面的元素进行分割后,rdd 变为:[‘我’, ‘要’, ‘通’, ‘过’, ‘使’, ‘用’, ‘flatMap’, ‘方’, ‘法’, ‘解’, ‘除’, ‘嵌’, ‘套’]
pandas 数据处理
pandas 读取 excel 文件
导入 pandas 库
import pandas as pd
读取 excel 文件
dataFrame 对象名 = pd.read_excel(‘文件路径’)
- 返回一个 DataFrame 对象
查看文件行数和列数
dataFrame 对象名.shape
- 返回一个显示文件行数和列数的元组对象
查看 excel 的每一列的列名
dataFrame 对象名.columns
设置每一列的列名
dataFrame 对象名.columns = [‘列名 1’, ‘列名 2’, …]
保存为 excel 文件
dataFrame 对象名.to_excel(‘文件路径 / 文件名.xlsx’)
爬虫
浏览器驱动
Edge 驱动链接:
xpath 解析
- 需要实例化一个 etree 的对象,并且需要将被解析的页面源码数据加载到该对象中
- 调用 etree 对象中的 xpath 方法结合着 xpath 表达式实现标签的定位内容的捕获
xpath 环境的安装
pip install lxml
实例化一个 etree
-
导入 etree
from lxml import etree
-
将本地的 html 文档中的源码数据加载到 etree 对象中:
etree.parse(html 源码的文件路径)
-
可以将从互联网上获取的源码数据加载到该对象中
etree.HMTL(‘获取的源码数据.txt’) —用 requests(…).content/requests(…).txt-
-
-
使用 xpath 方法
xpath(‘xpath 表达式’)
-
xpath 表达式
/ 符号表示层级关系
// 表示多个层级,可以表示从任意位置开始定位
如
path = etree 对象名.xpath(’/html/head/title’)
path = etree 对象名.xpath(’/html/body/div’) —与下面的一样
path = etree 对象名.xpath(’//div’)
属性定位
标签 [@class = ‘属性标签’]
path = tree.xpath(’//div[@class = “module-item-pic”]’)标签名 [@属性名称] img[@‘data-original’] 或标签名 [@属性名称 = ‘属性名’]
获取文本用 /text()
eg. 美团二手房的房价
text = tree.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[2]/div[1]/a/div[2]/div[2]/p[1]/span[@class = "property-price-total-num"]/text()'')
selenium 模块
- 可以便捷的获取网站中动态加载的数据
- 便捷的实现模拟登录
什么是 selenium
- selenium 是基于浏览器自动化的一个模块。指可以通过编辑相关的 python 代码,让 python 表示一些浏览器的行为动作,让 python 的代码触发到浏览器当中,浏览器则根据代码的指示完成自动化的相关动作
pip install selenium
1. 配置驱动
实例化一个驱动对象名 = webdriver.Edge(“驱动配置的具体路径”)
设置等待时间
驱动对象名.implicitly_wait(时间单位秒)
让浏览器打开网站
驱动对象名.get(网站链接)
关闭浏览器
驱动对象名.quit()
2. 选择元素
导入库
from selenium.webdriver.common.by import By
注意:find_element 方法是返回第一个要找的值,find_elements 是返回全部要找的值
根据 ID 查找
#旧版:element = 驱动对象名.find_element_by_id ("具体的 ID 相关的值")
element = 驱动对象名.find_element(By.ID, “具体的 ID 相关的值”) ---- 即 ID = “ 值”
根据 CSS 选择器查找
#旧版:element = 驱动对象名.find_element_by_css_selector("css 选择器")
element = 驱动对象名.find_element(By.CSS_SELECTOR, "css 选择器")
想知道 css 选择器有哪些?
获取网页中 css 选择器的方法:

按照 CLASS.NAME 查找
#旧版:element = 驱动对象名.find_element_by_css_name(“class 属性对应的值”)
element = 驱动对象名.find_element(BY.CLASS_NAME, "class 属性对应的值")
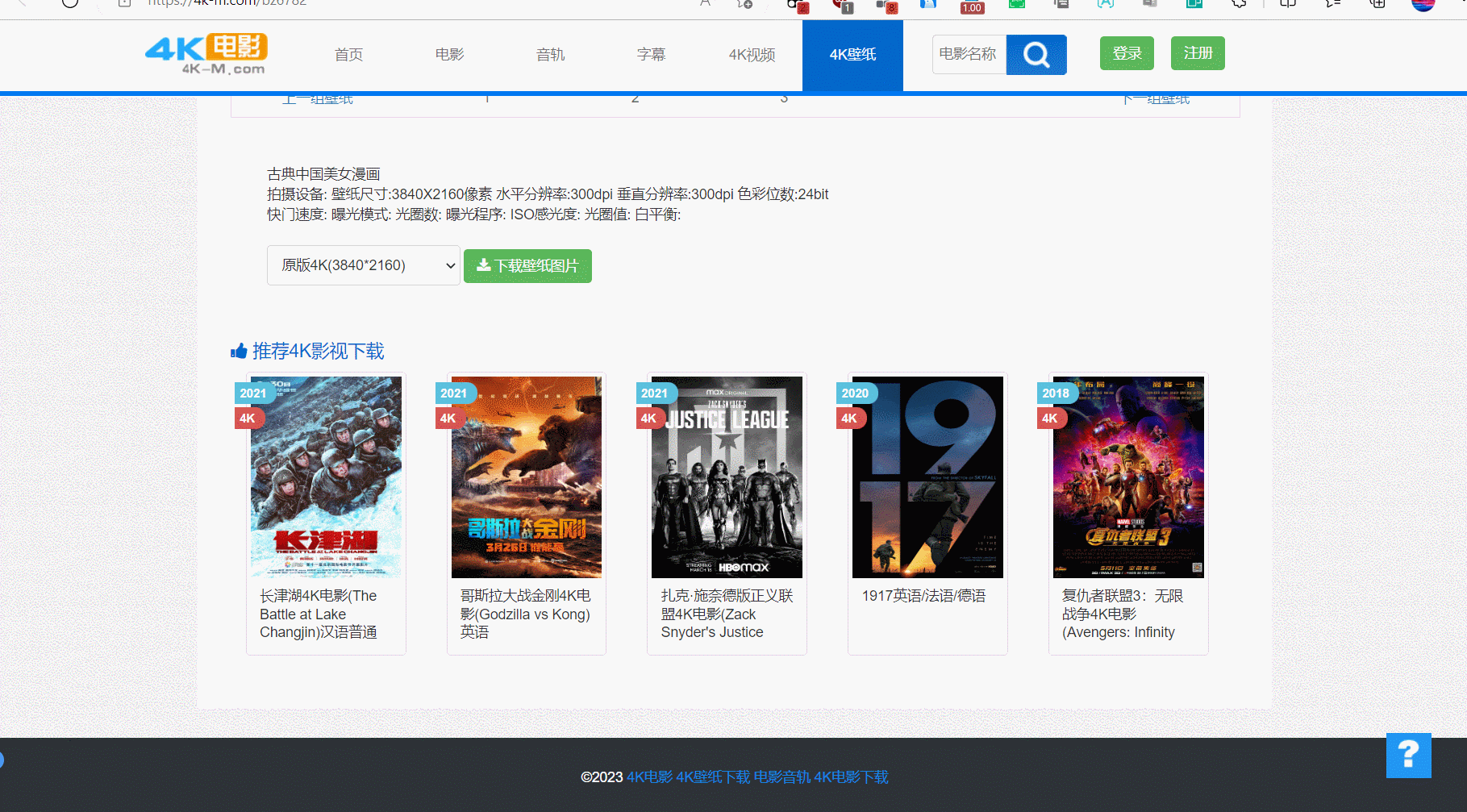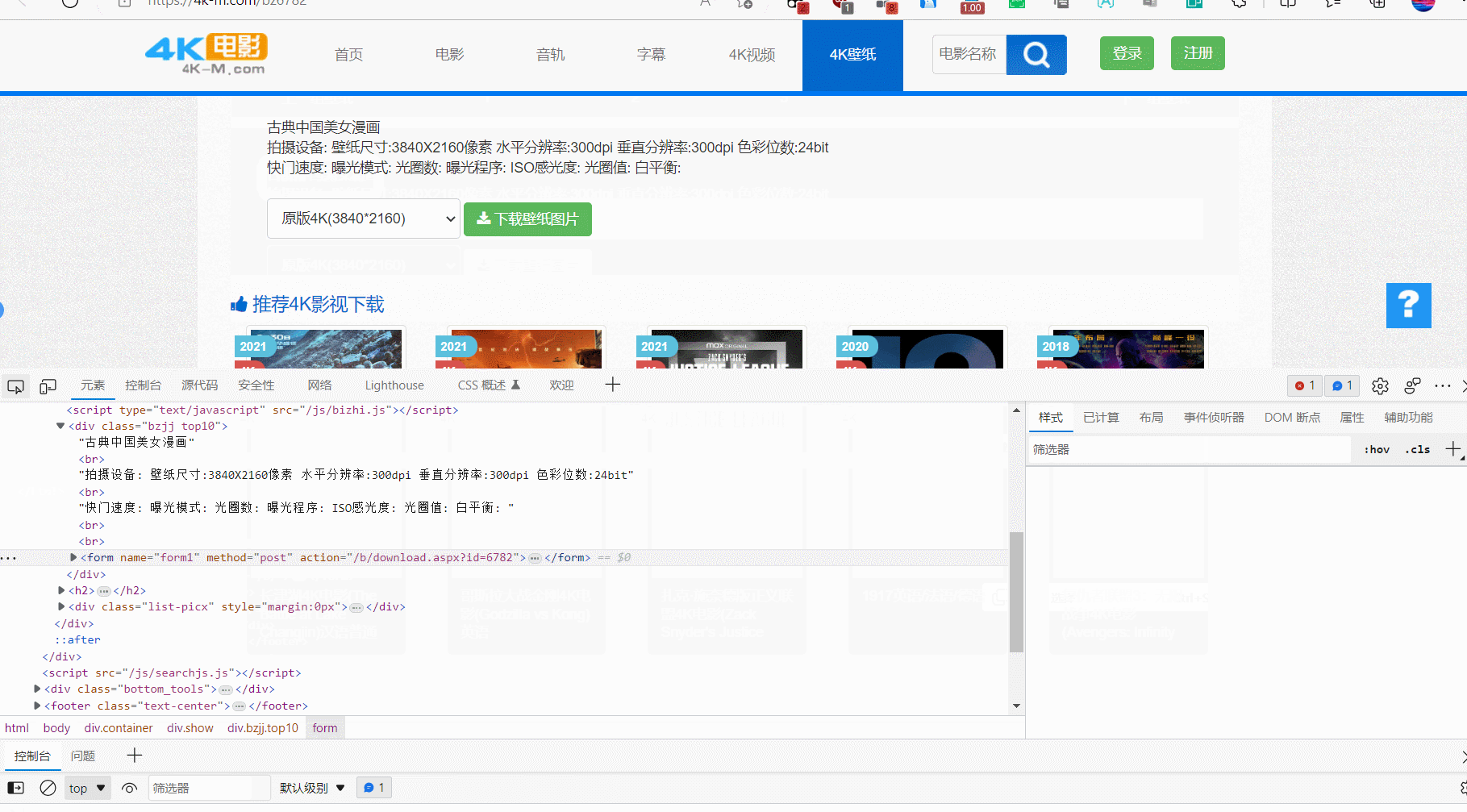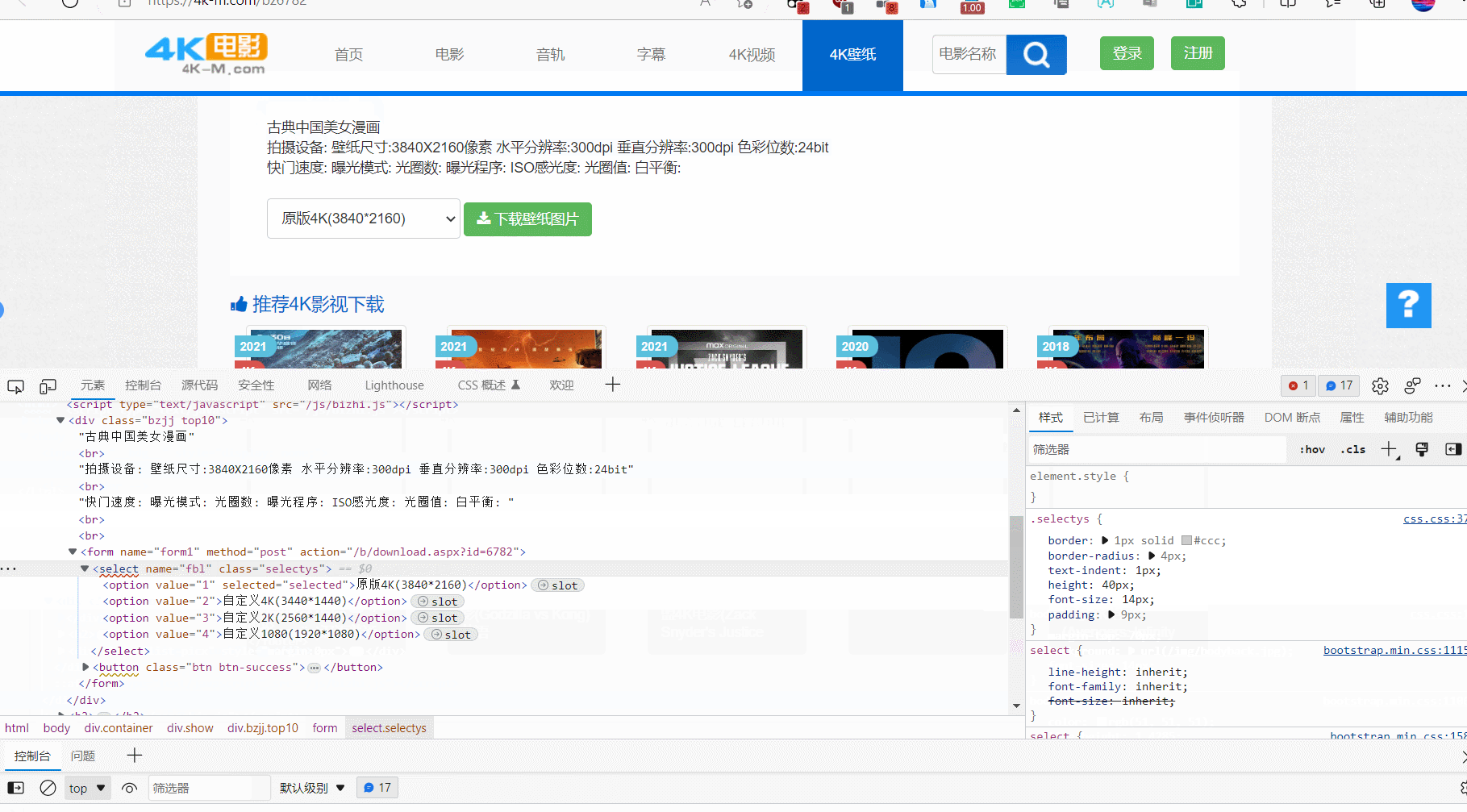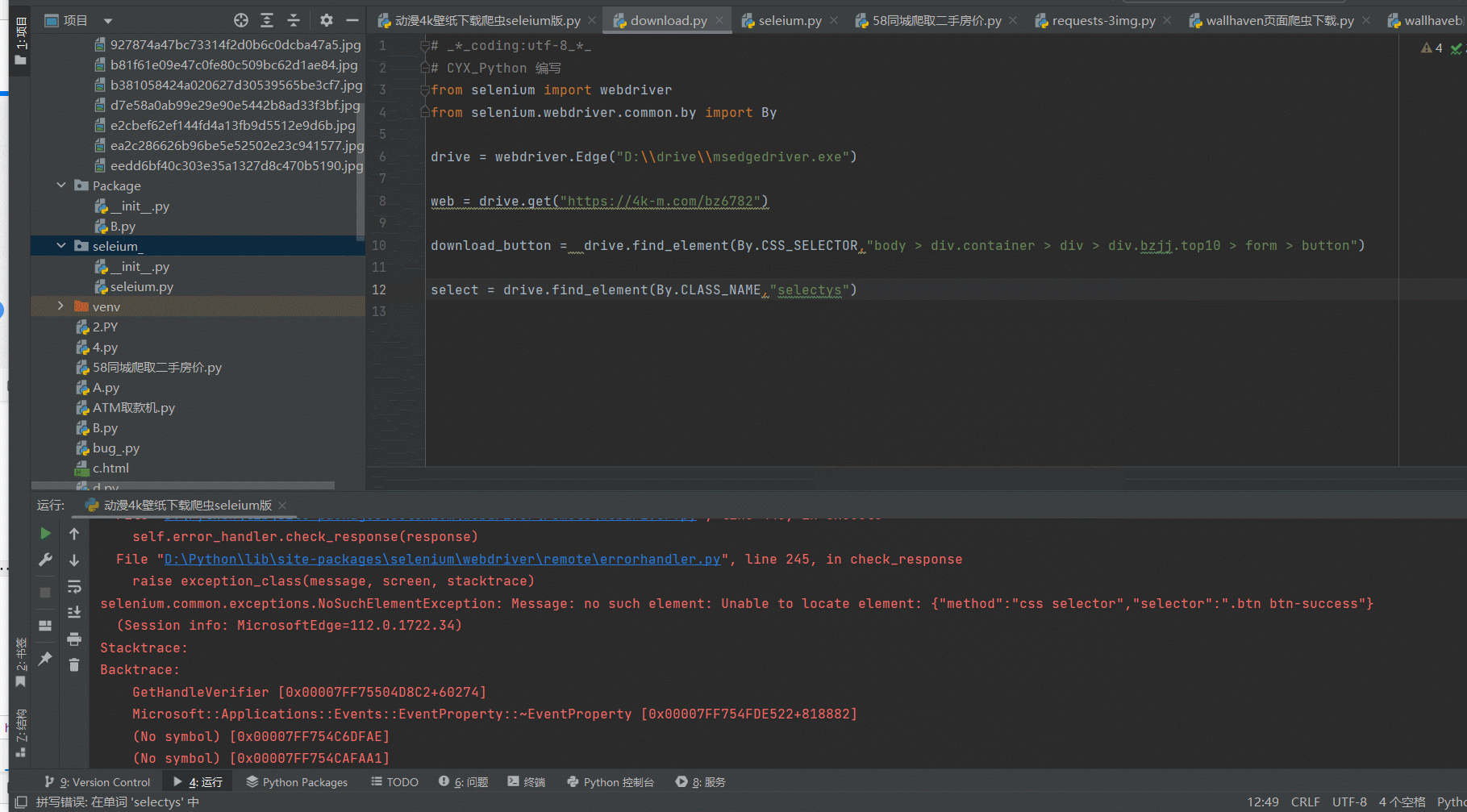
按 tag_name 查找 -- 即标签名
element = 驱动对象名.find_element(BY.TAG_NAME, "tag 属性")
3. 操作元素
输入文字操作
element.send_keys(“文本”) #用于文本框
点击操作
element.click() #用于按钮、超链接、单选框、多选框
下拉框选择
from selenium.webdriver.support.select import Select
下拉框镀对象名 = Select(要选的下拉框的元素定位)
选择下拉框的值
下拉框对象名.select_by_value(“option 里面 value 对应的值,注意不是字符串”)

一行代码解决
Select(驱动对象名.find_element(…)).select_by_value(“option 里面 value 对应的值,注意不是字符串”)
根据下拉框的文本信息对下拉框进行选择
下拉框对象名.select_by_visible_text(“option 里面对应的字符串”) ---- 即可以网页可以直接看到的

4. 切换窗口
因为 iframe 导致的操作失败可以尝试使用该方法
驱动对象名.switch_to.frame(“要切换的 iframe 名”)
切换后选择新窗口的元素
驱动对象名.switch_to.frame(要选的新窗口的元素的定位)

5. 模拟鼠标移动
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
实例化鼠标对象名 = ActionChains("驱动的具体路径")
鼠标对象名.move_to_element(
drive.find_element(By.XPATH,'xpath表达式要鼠标移动的具体路径')
).perform()
浏览器当前页面最大化
驱动对象名.maximize_window()
6. 无头模式窗口最大化
# 无可视化界面设置 #
#edge_options 表示创建一个浏览器设置类的对象
edge_options = webdriver.EdgeOptions()
# 使用无头模式
edge_options.add_argument('--headless')
# 禁用GPU,防止无头模式出现莫名的BUG
edge_options.add_argument('--disable-gpu')
edge_options.add_argument('blink-settings=imagesEnabled=false') # 不加载图片, 提升速度
edge_options.add_argument('--headless')
#无头模式通过maximize_window()函数将webdriver驱动的窗口设置为全屏会失效,此时解决办法
#是通过pyautogui来获取屏幕尺寸,然后webdriver的add_argument()函数来设置窗体大小就行了
driver_width, driver_height = pyautogui.size() # 通过pyautogui方法获得屏幕尺寸
edge_options.add_argument('--window-size=%sx%s' % (driver_width, driver_height)) # 设置无头浏览器窗口大小
PySide6/PyQT 5
Python 小编程
1. 石头剪刀布游戏
x='Yes'
while x=='Yes':
import random
user_choice=input('请在石头、剪刀、布中选择出一个:')
a=random.choice(['石头','剪刀','布'])
print('电脑出:'+a)
if a==user_choice:
print('你们是平手')
if a=='石头' and user_choice=='剪刀':
print('你输了')
if a=='石头' and user_choice=='布':
print('你赢了')
if a=='剪刀' and user_choice=='石头':
print('你赢了')
if a=='剪刀' and user_choice=='布':
print('你输了')
if a=='布' and user_choice=='石头':
print('你输了')
if a=='布' and user_choice=='剪刀':
print('你赢了')
if x==input('您是否还要继续玩?\n是请按:Yes,否请按任意按键'):
continue
else:
break
2.ATM 取款机
user_name=input('请输入您的姓名:')
user_money=5000000
while True:
def main():
a='欢迎' + user_name + '先生来取款,请您选择您所需要的操作'
print(a.center(48,'-'))
print('1.查询您的余额'.center(58, '-'))
print('2.存款'.center(60, '-'))
print('3.取款'.center(60, '-'))
print('4.退出'.center(60, '-'))
def search():
print('您目前的余额为:', user_money)
return main()
def deposit():
global user_money
deposit_money=eval(input('请输入您要存款的金额:'))
user_money=deposit_money+user_money
print('存款成功,您目前的账户余额为:',user_money)
return main()
def withdrawal():
global user_money
withdrawal_money = eval(input('请输入您要取款的金额:'))
user_money = user_money-withdrawal_money
print('存款成功,您目前的账户余额为:', user_money)
return main()
def exit():
print('已退出系统,欢迎您再次使用')
user_choise=eval(input('请您选择操作:'))
if user_choise==1:
search()
if user_choise == 2:
deposit()
if user_choise == 3:
withdrawal()
if user_choise == 4:
exit()
if user_choise not in range(1,5):
print('已退出系统,欢迎您再次使用')
print(main())
break
.png)

评论区